Covid Thailand Trends
Thailand Covid testing and case data gathered and combined from various sources for others to download or view
Project maintained by Hosted on GitHub Pages — Theme by mattgraham
Thailand COVID-19 Data
Note Share via https://djay.github.io/covidthailand
Thailand COVID-19 case/test/vaccination data gathered and combined from various government sources for others to view or download.
- Updated daily 8-9am summary info, 1-3pm from full briefing. Testing data is updated every 1-3 weeks.
![]() .
.
Cases | Active Cases | Deaths | Testing | Vaccinations | Downloads | About
NEW Excess Deaths
Disclaimer
Data offered here is offered as is with no guarantees. As much as possible government reports and data feeds have been used effort has gone into making this data collection accurate and timely. This sites only intention is to give an accurate representation of all the available Covid data for Thailand in one place.
Links to all data sources are including in Downloads
Cases
Daily Averages as % of Peak
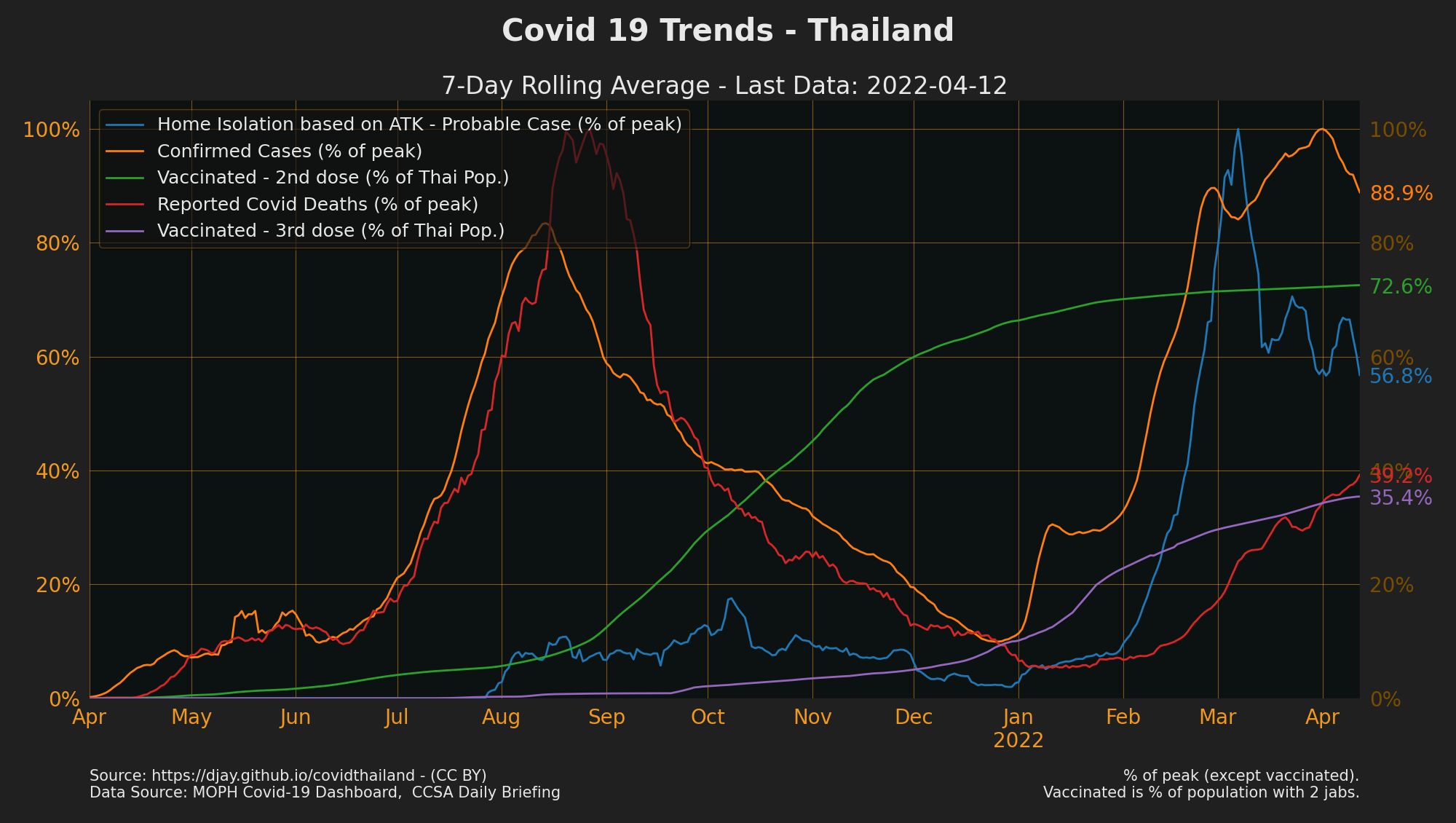
- For predictions of total infections/deaths see IHME Thailand,
IHME Thailand Report,
ICL Thailand,
LSHTM Thailand, OWID Covid Models for Thailand, Google mobility data - Sources: CCSA Daily Briefing, MOPH daily situation report
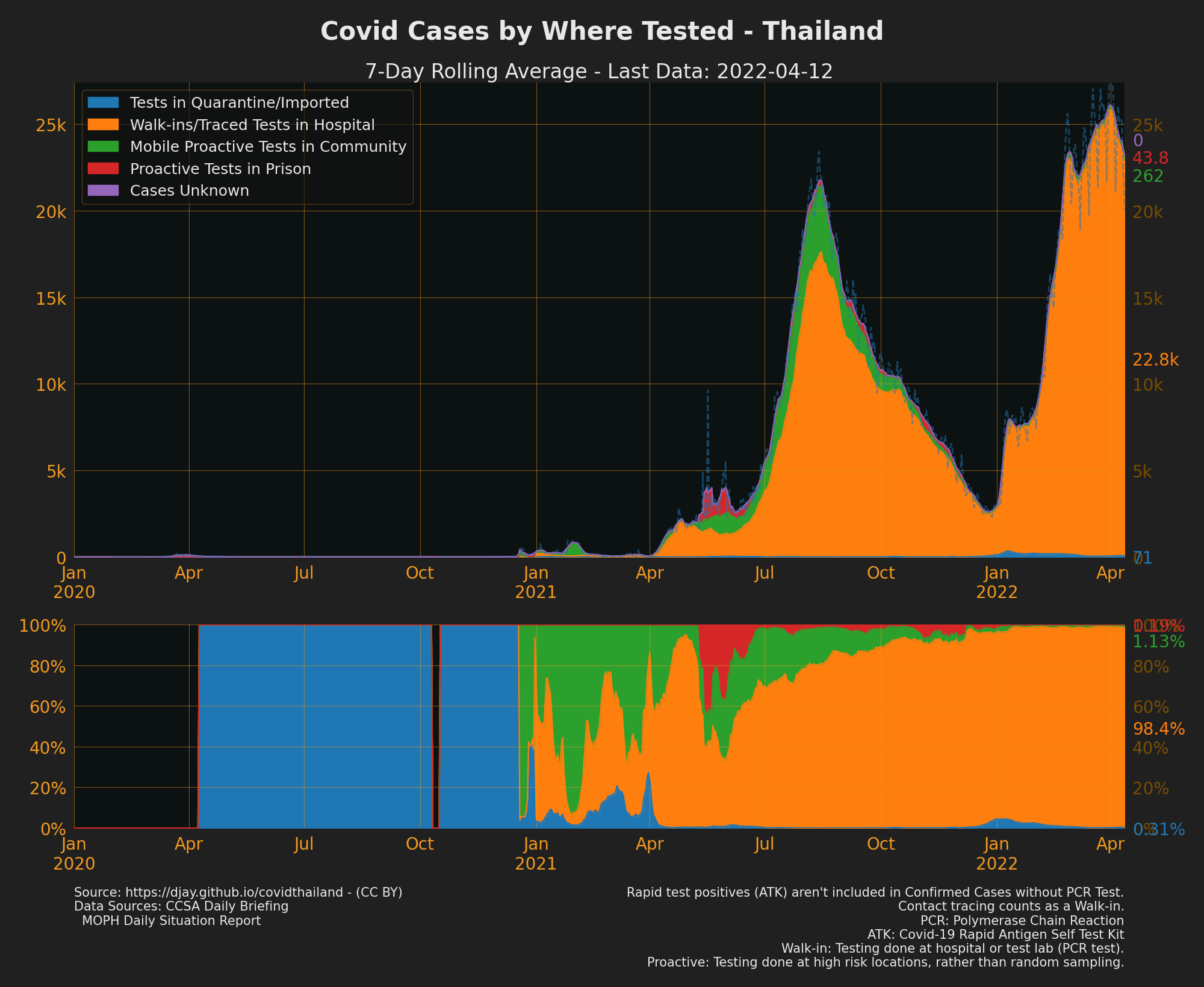
Cases by Where Tested
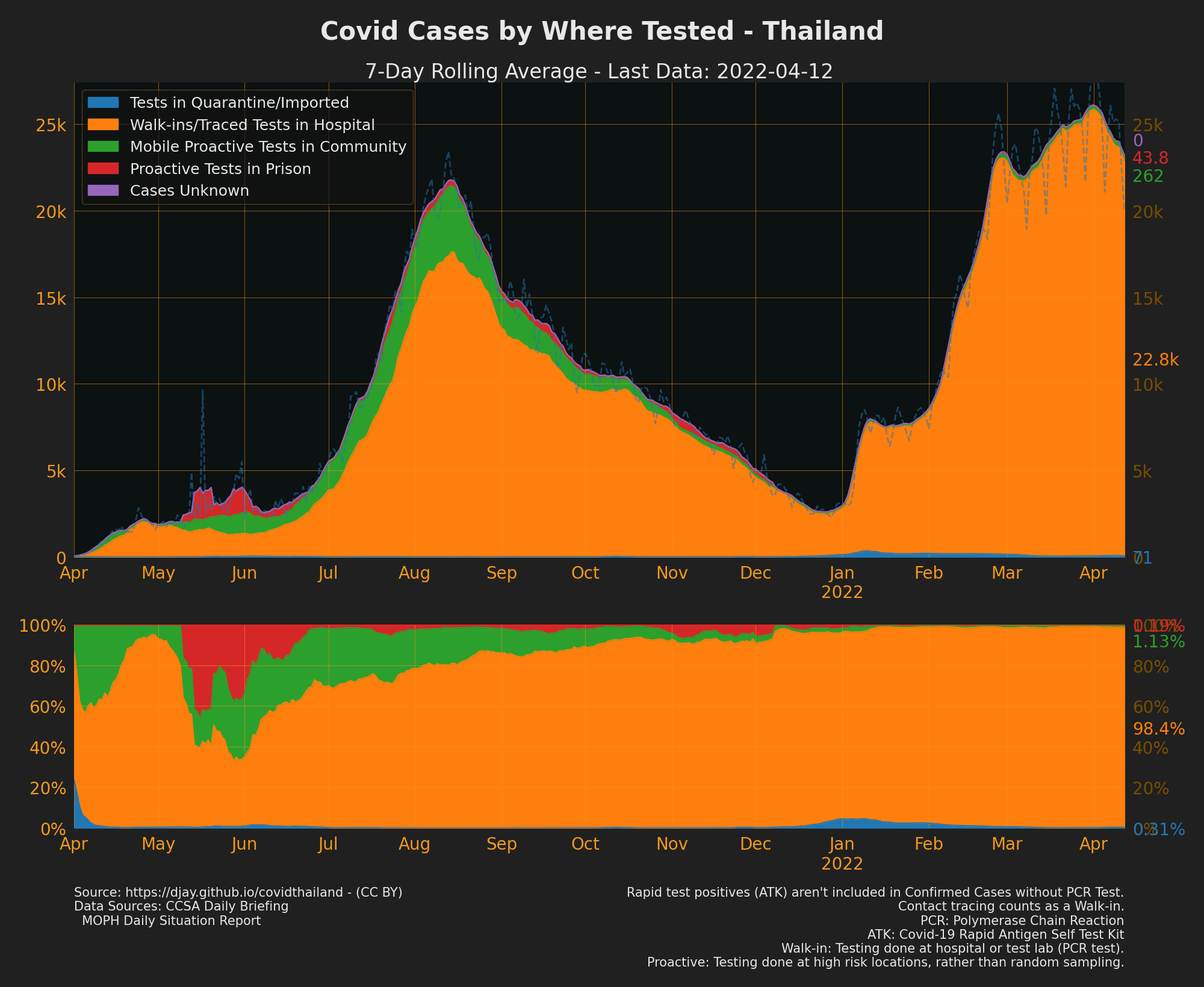
- Source of Confirmed Cases: 2020-2021
- Contact tracing normally counts as a “Walk-in”
- Proactive tests are normally done at specific high risk locations or places of known cases, rather than random sampling (but it’s possible random sampling may also be included).
- Sources: CCSA Daily Briefing, MOPH daily situation report
{kind=link}
Cases by Risk Group
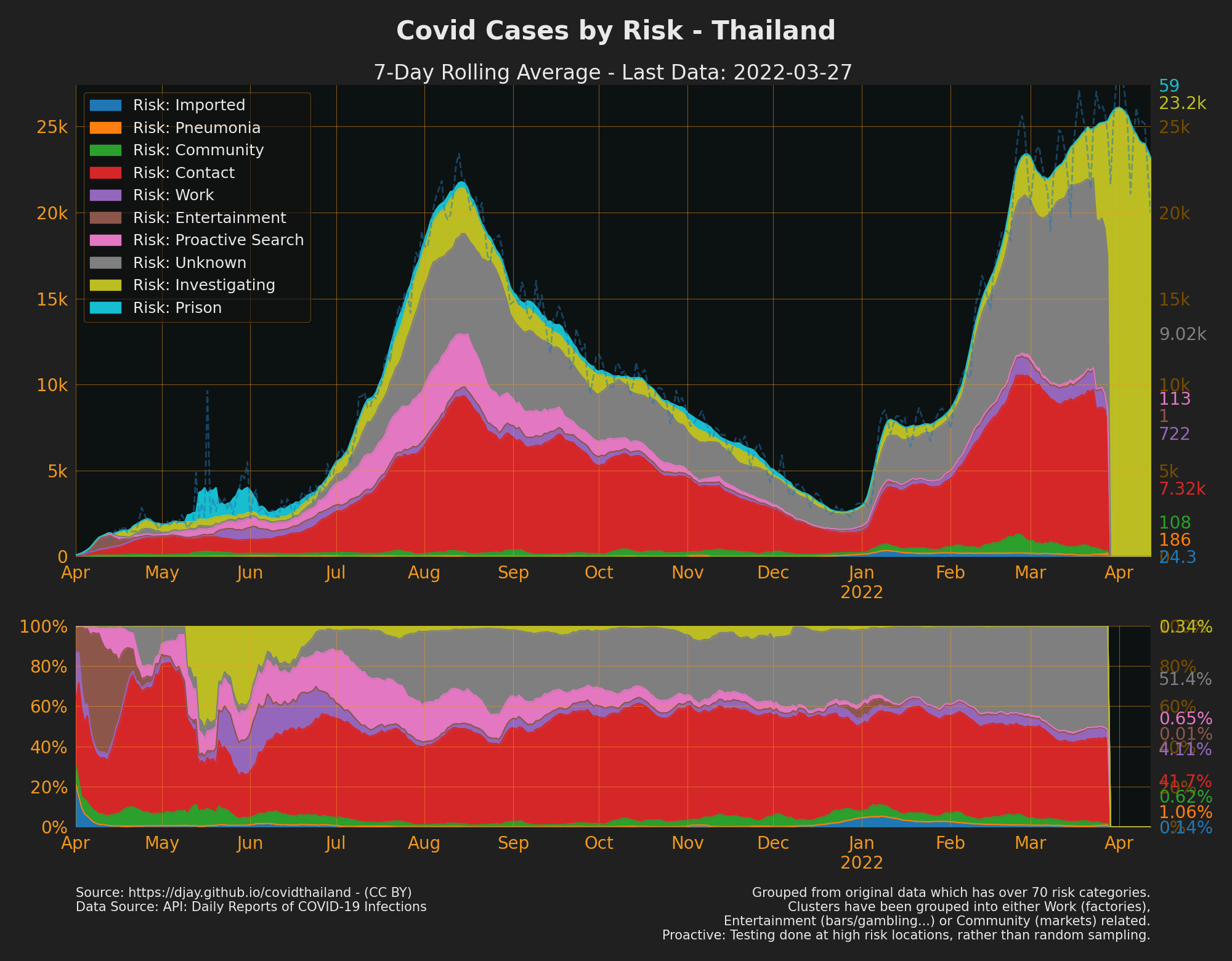
- Grouped from original data which has over 70 risk categories. Clusters have been grouped into either Work (Factories), Entertainment (bars/gambling etc) or Community (markets) related.
- Note: SS Cluster is classified as “Work”, but some other market clusters are classified as “Community”. This is because there isn’t enough data to separate out SS cluster cases between those from factories and those from the market. This could change later.
- Risk is most likely determined as part of the PUI criteria process?
- Cases by Risk: Full Year
- Source: API: Daily reports of COVID-19 infections
{kind=link}
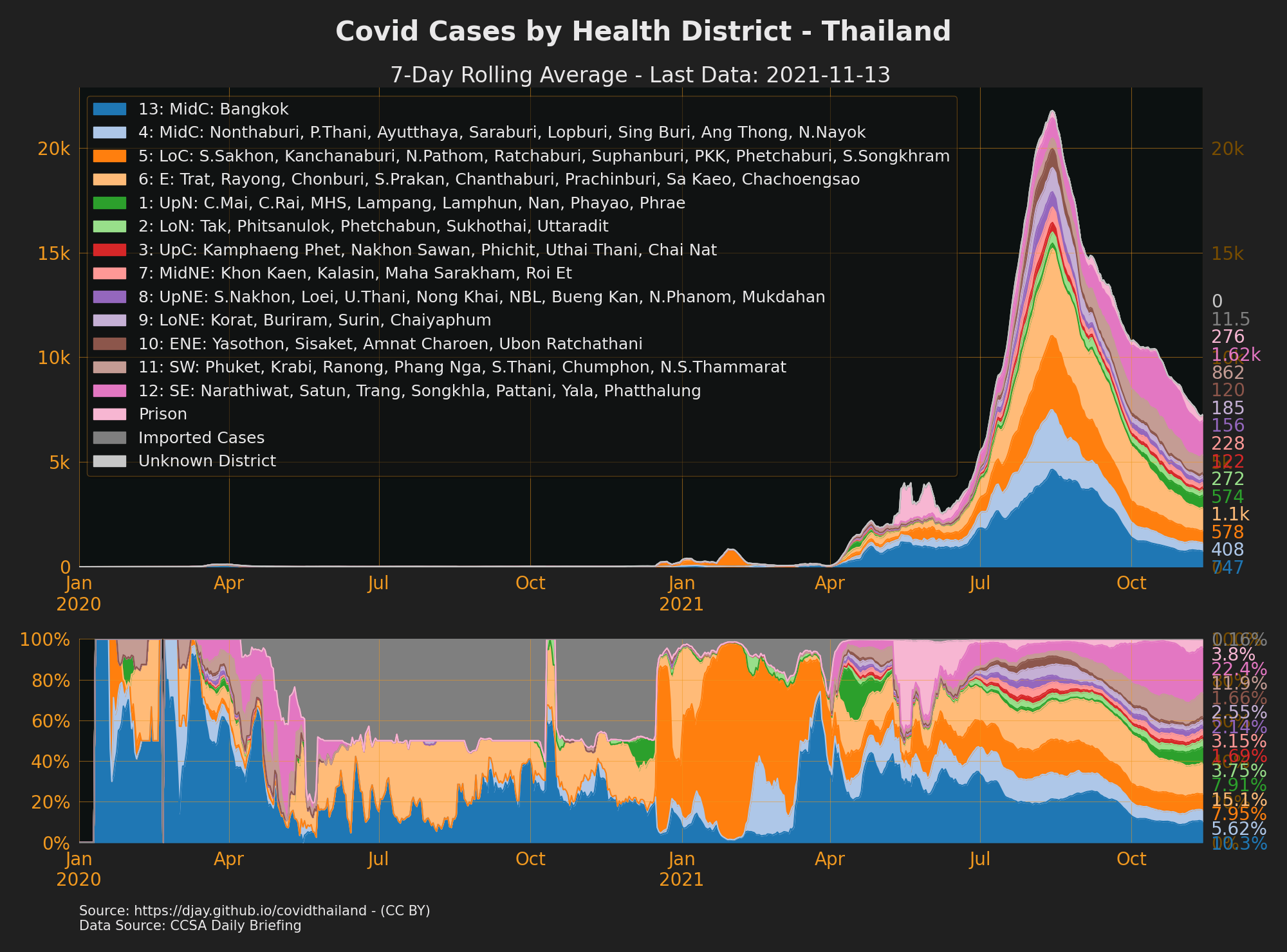
Cases by Health District
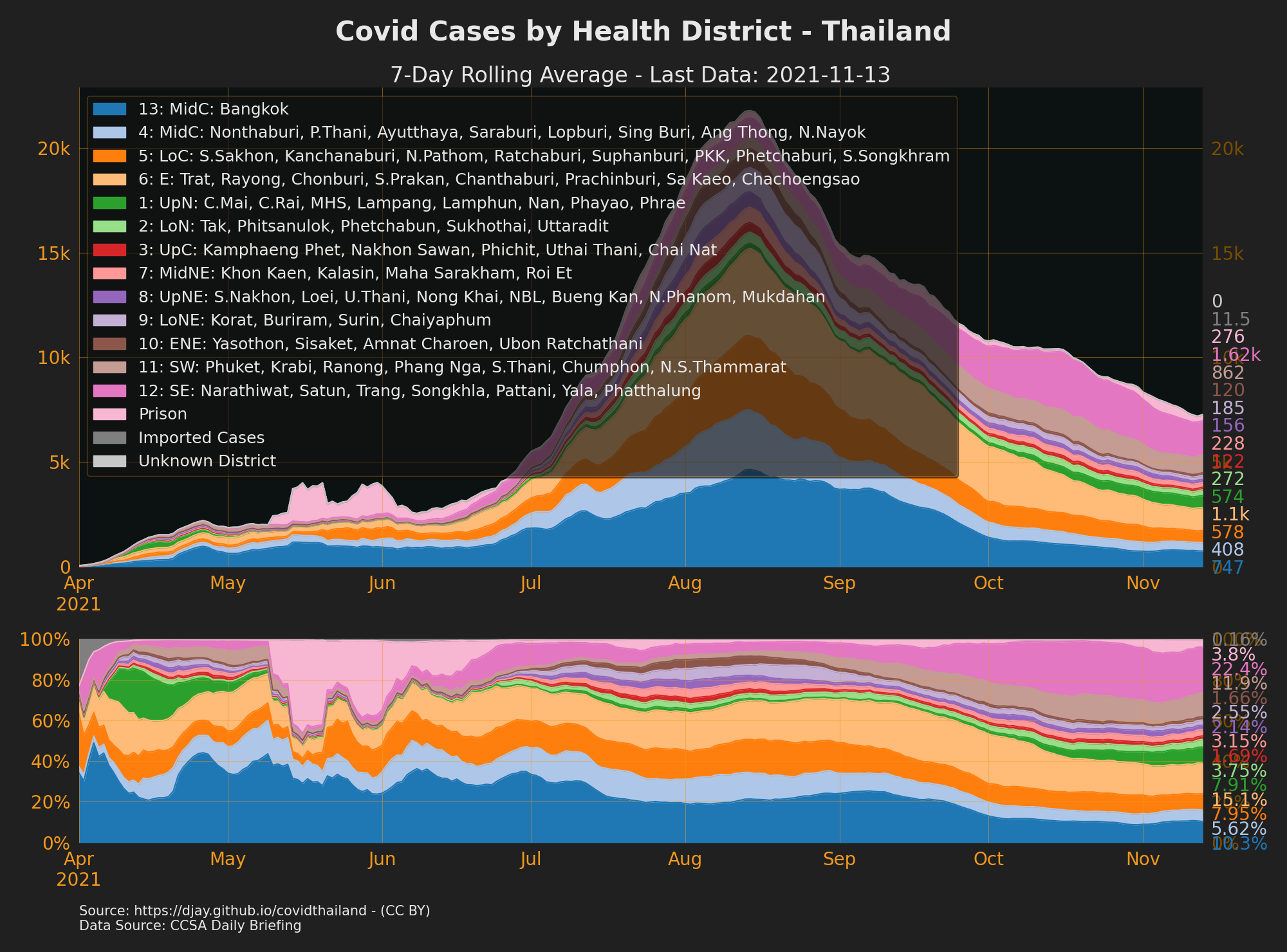
- To see cases for every province go to The Researcher Covid Tracker
- Cases by Health District: Full Year
- Thailand Health Districts
- You can also see Cases by District broken down by walk-in vs proactive but there is no longer a data source to keep this updated.
- Sources: CCSA Daily Briefing
{kind=link}
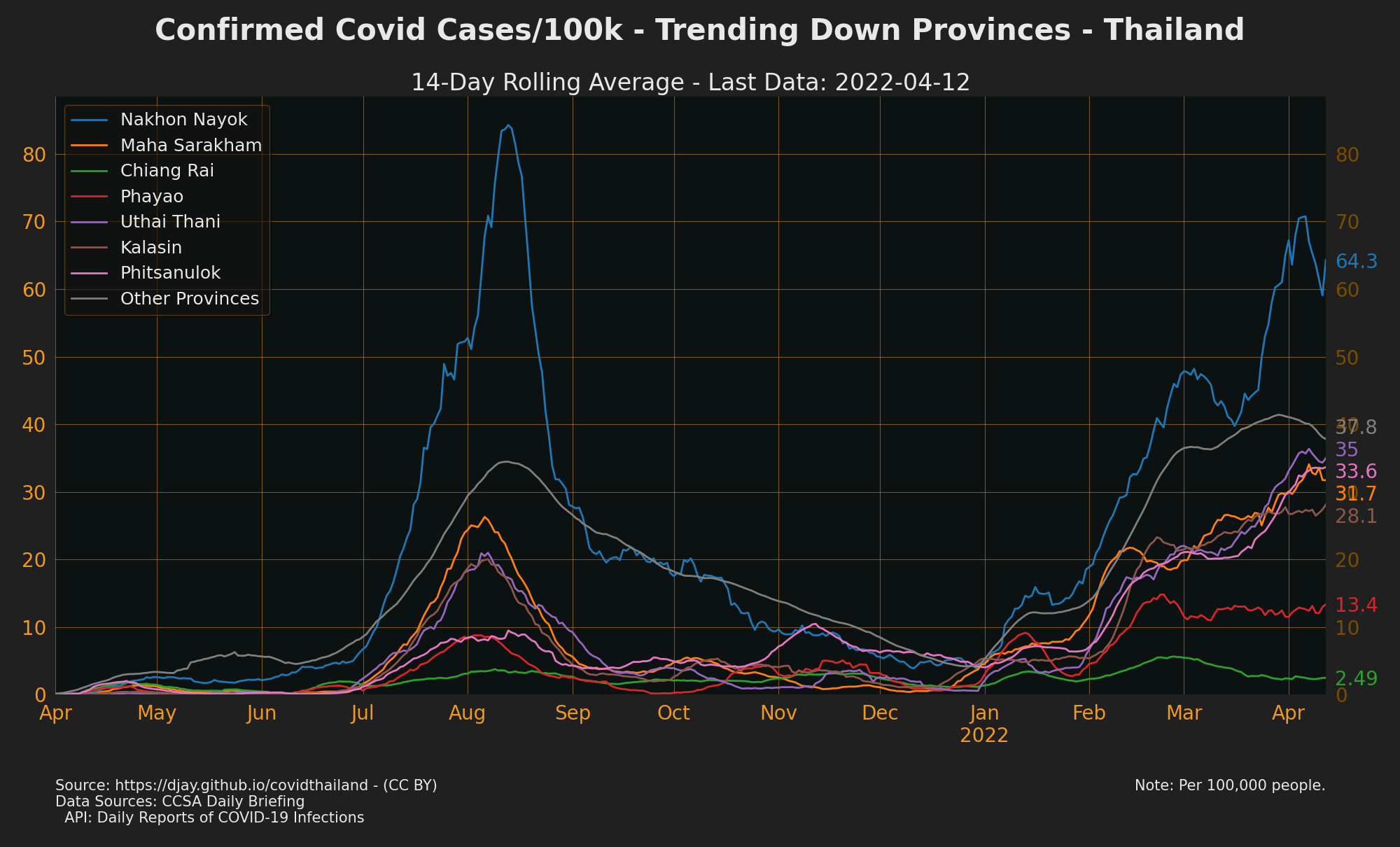
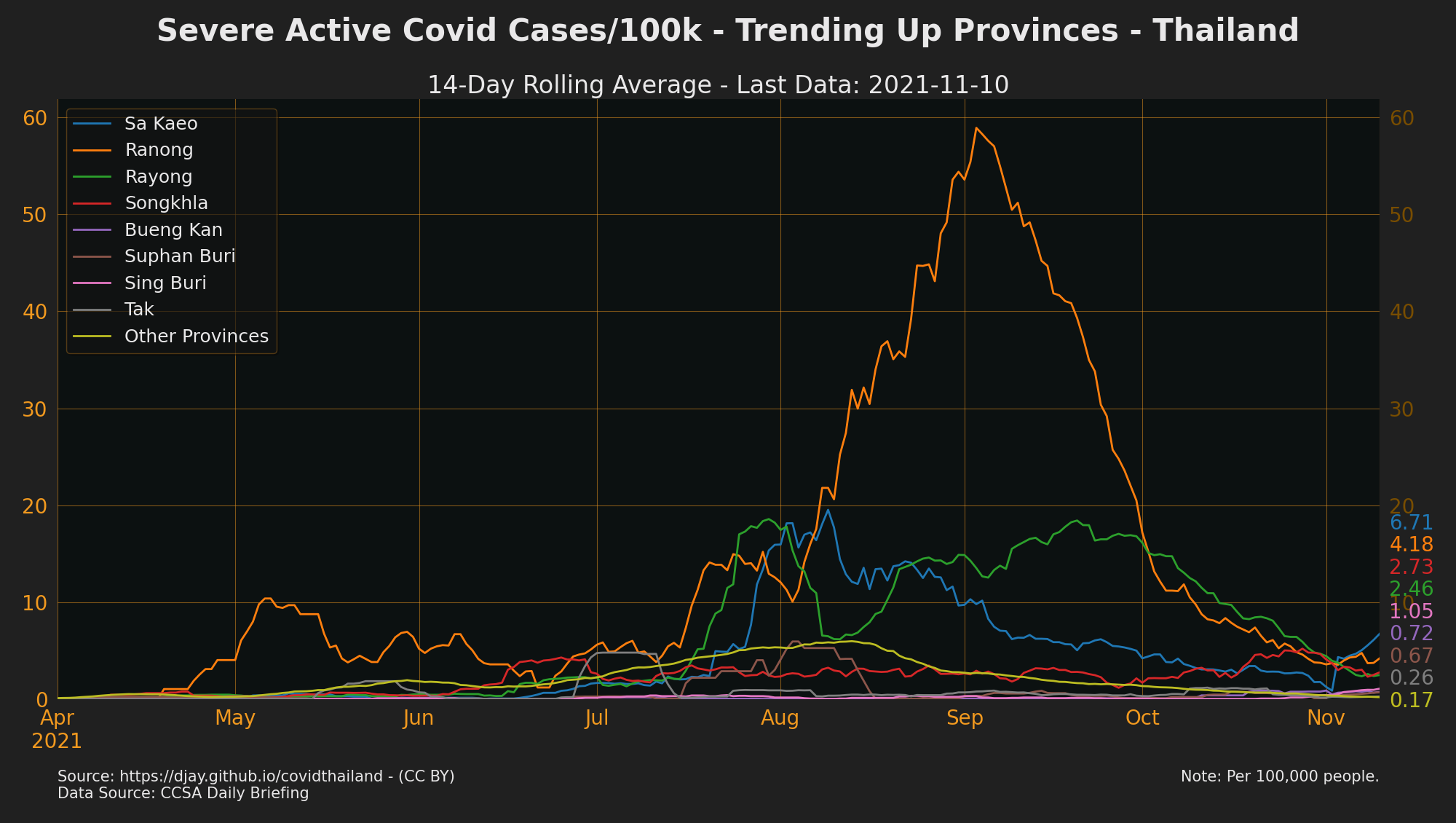
Provinces with Cases Trending Up
To see cases for every province go to The Researcher Covid Tracker
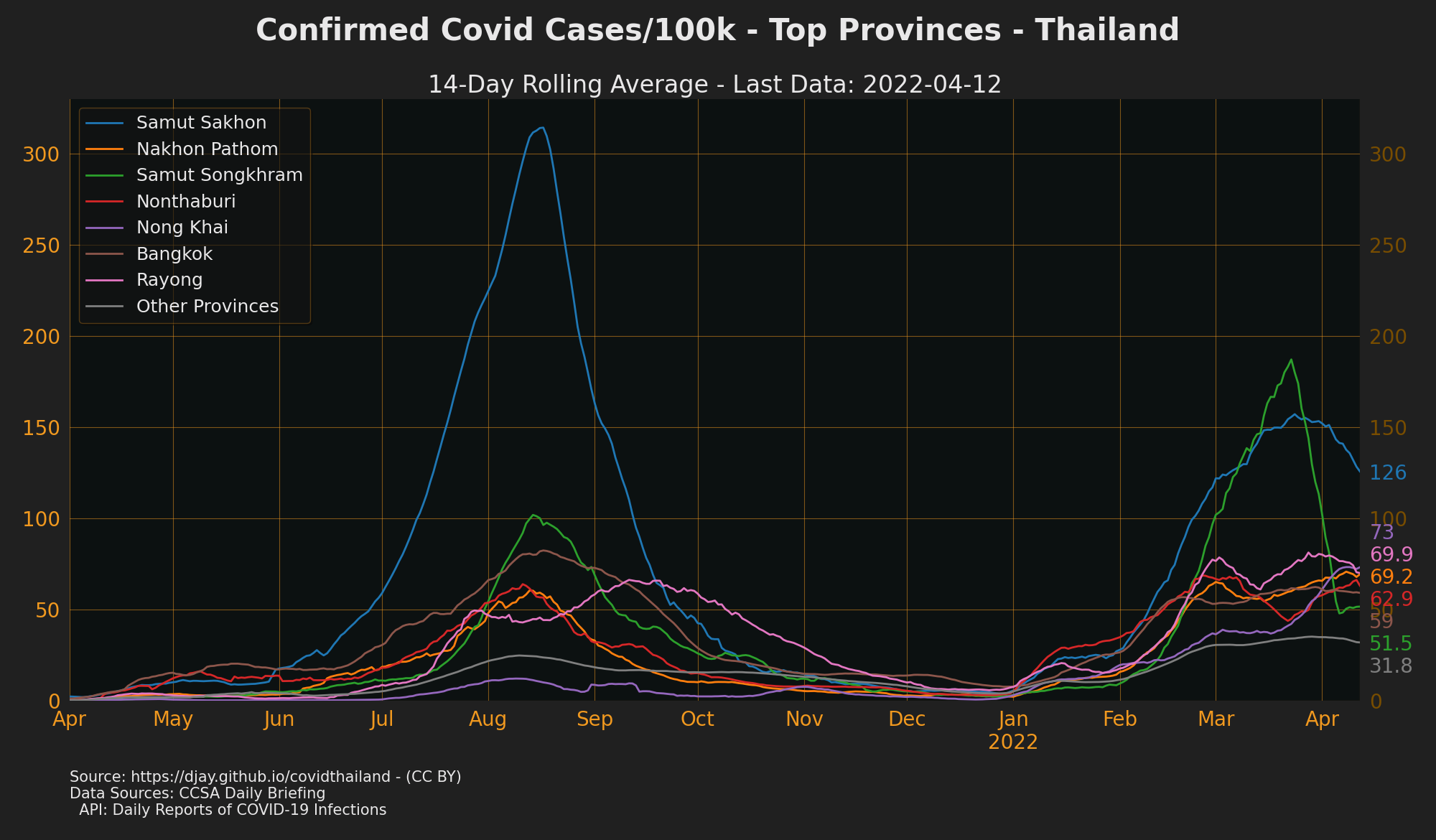
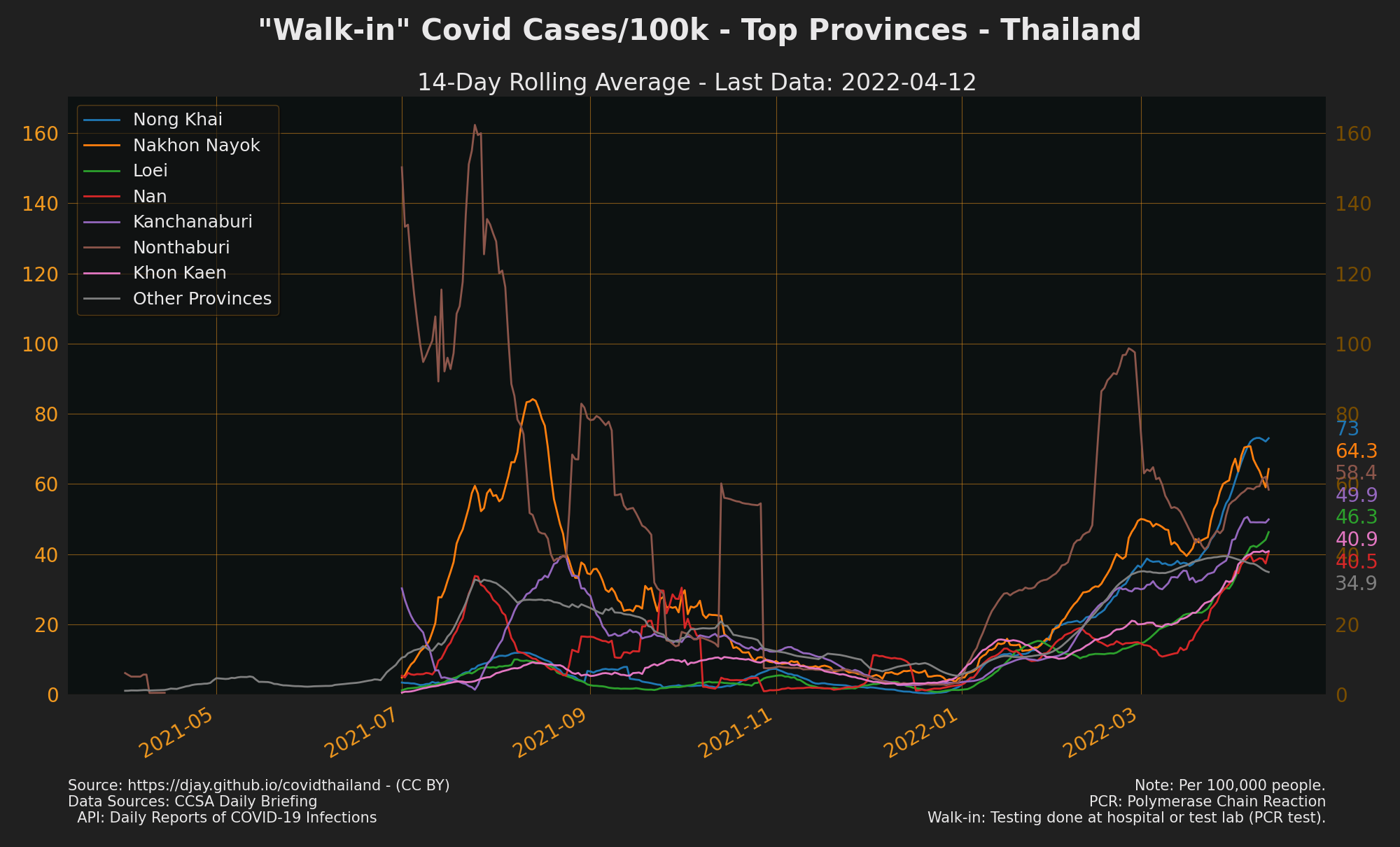
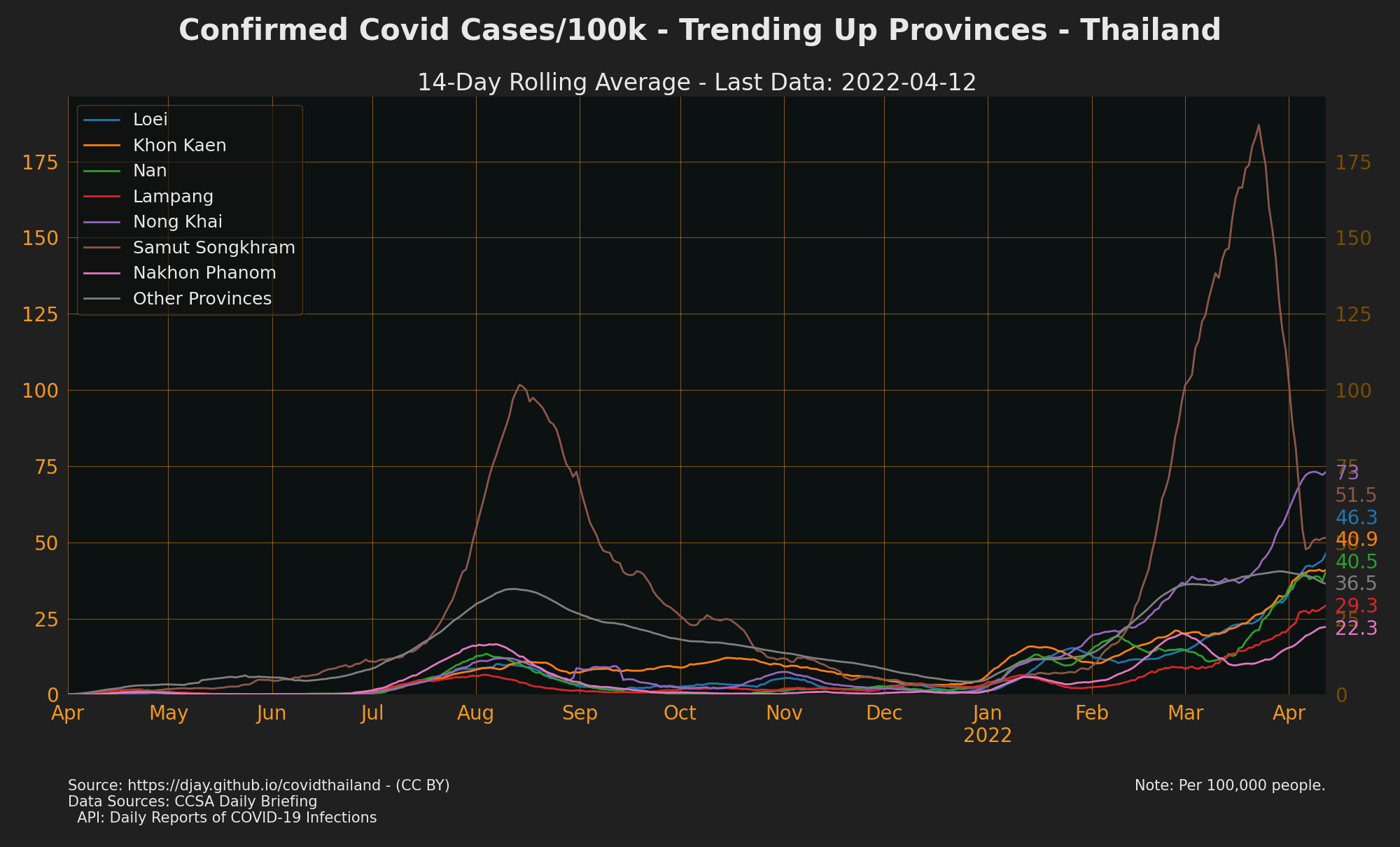

-
Sources: CCSA Daily Briefing, API: Daily reports of COVID-19 infections
-
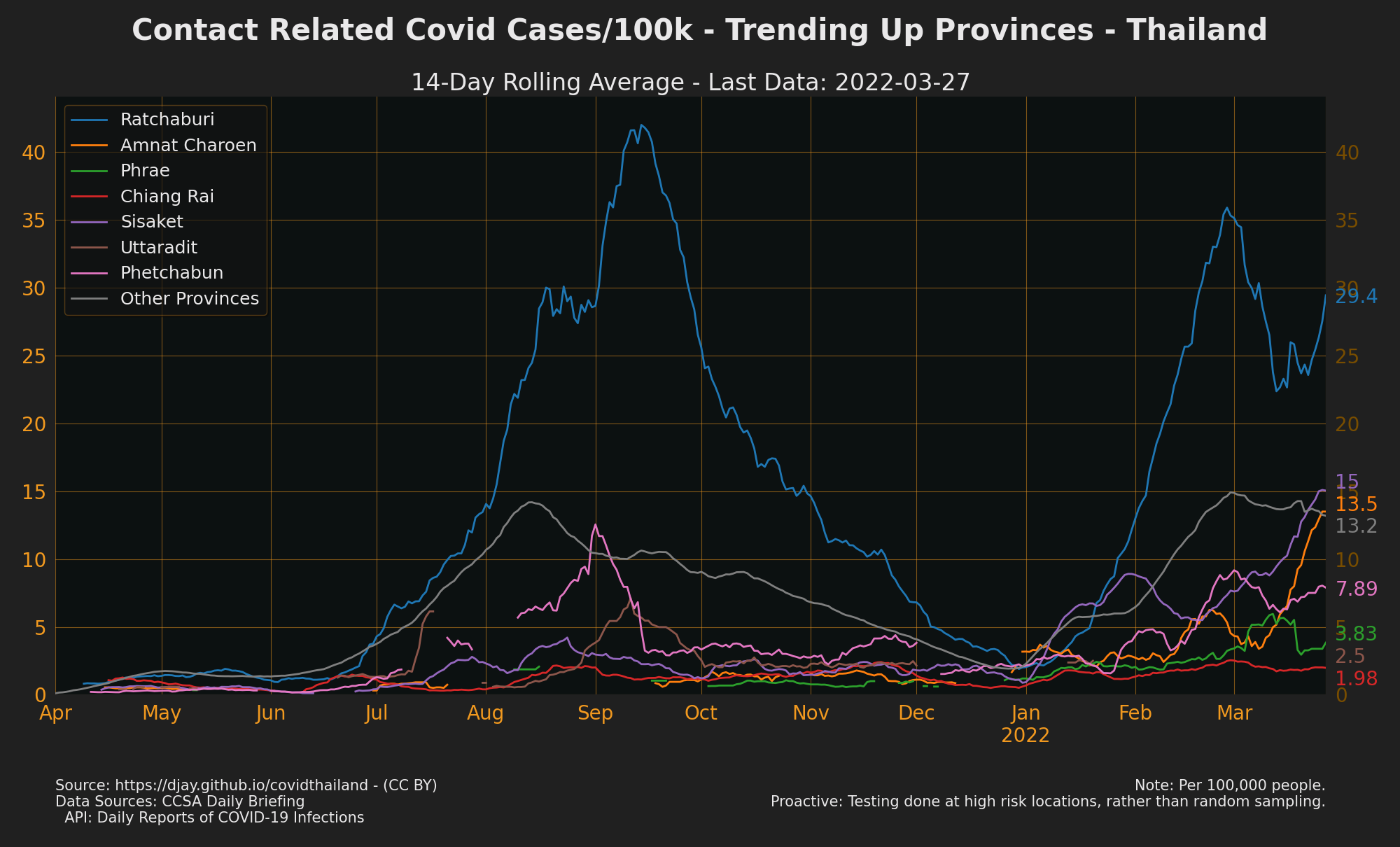
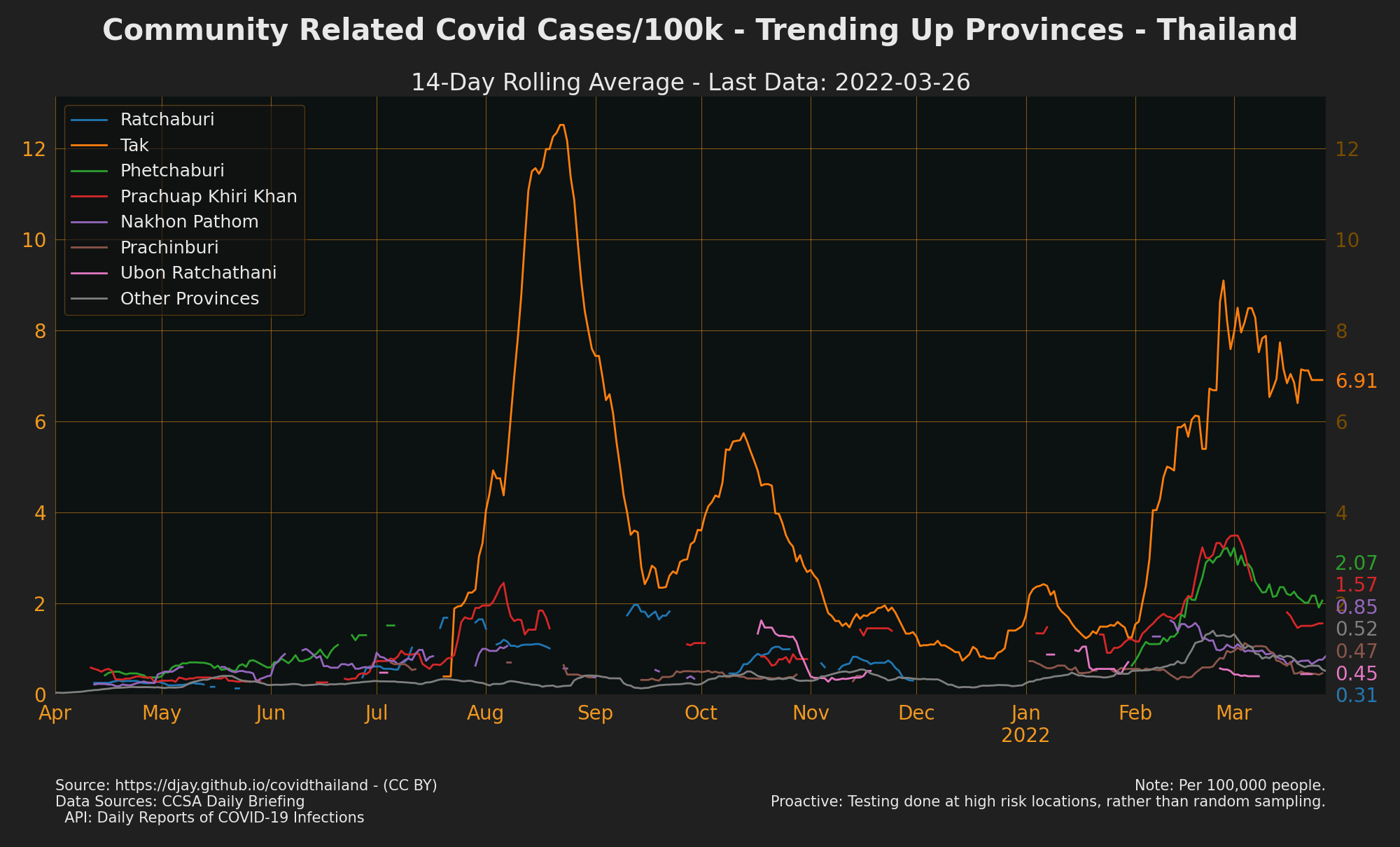
see also Trending Down Confirmed Cases, Trending Up Contact Cases, Trending Up Unknown Cases, Trending Up Community Cases, Trending Up Work Cases and Trending Up Proactive Cases
Cases by Age
{kind=link}
{kind=link}
{kind=link}
{kind=link}
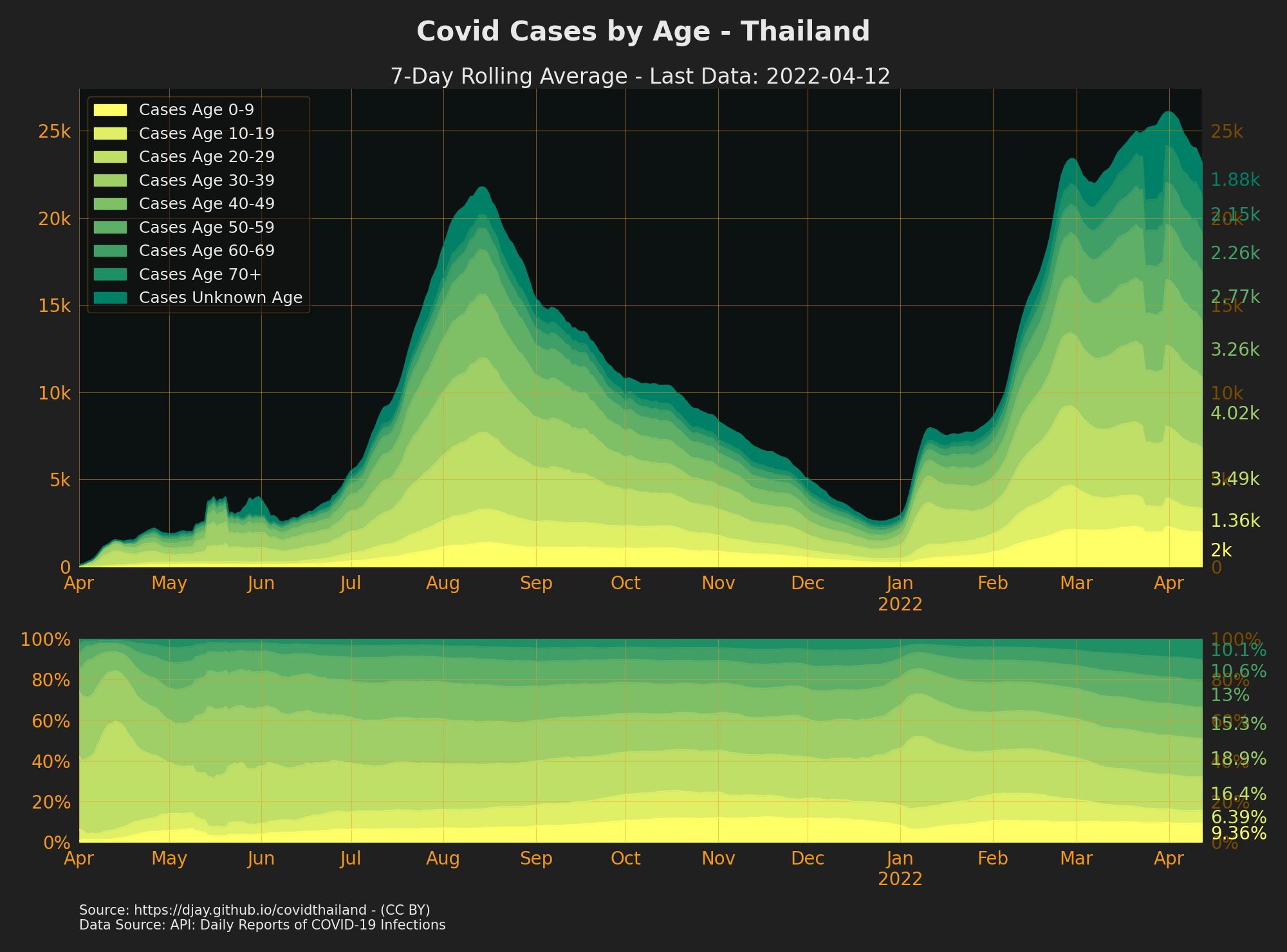
){kind=link}
Active Cases/Hospitalisations
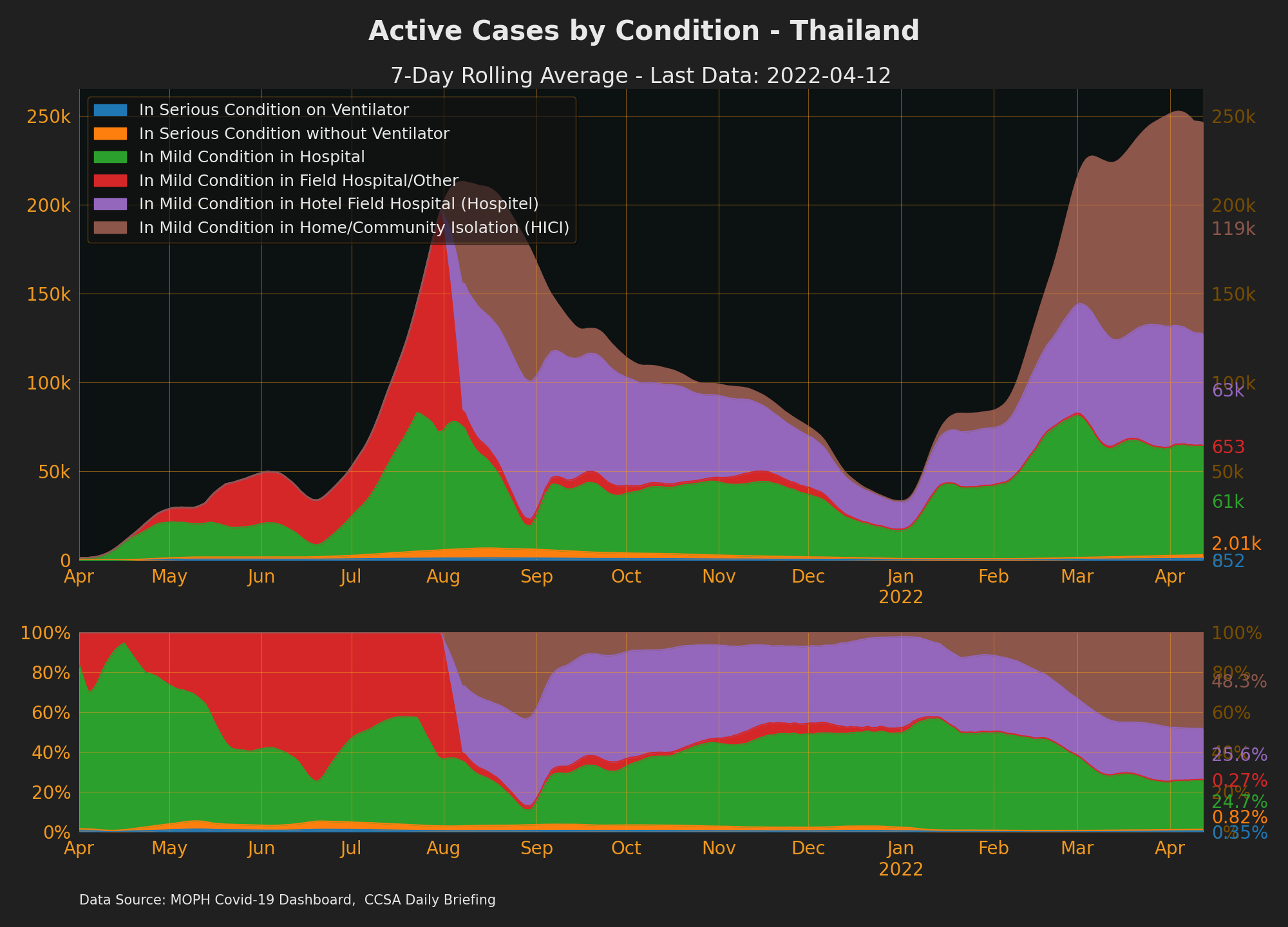
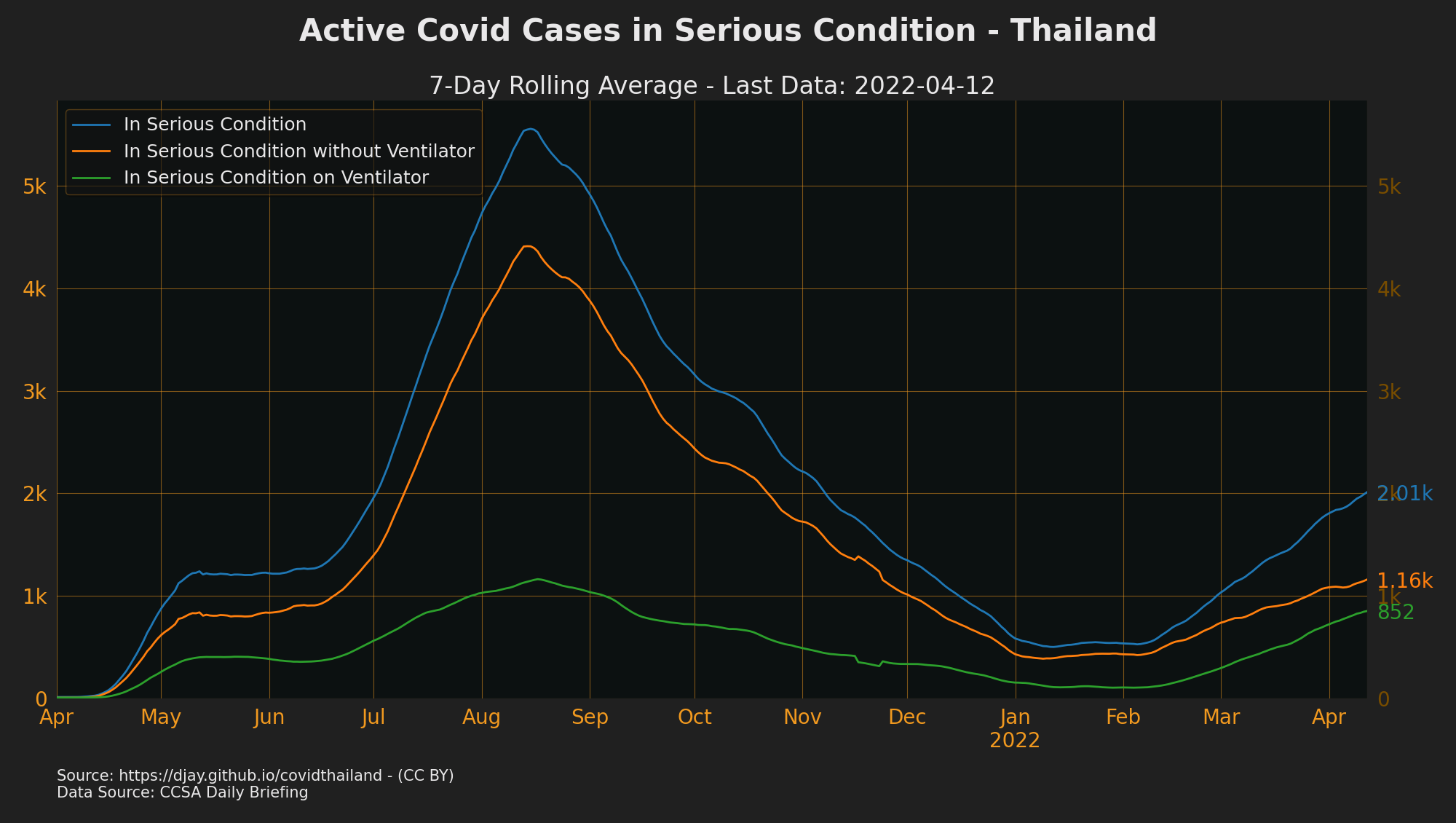
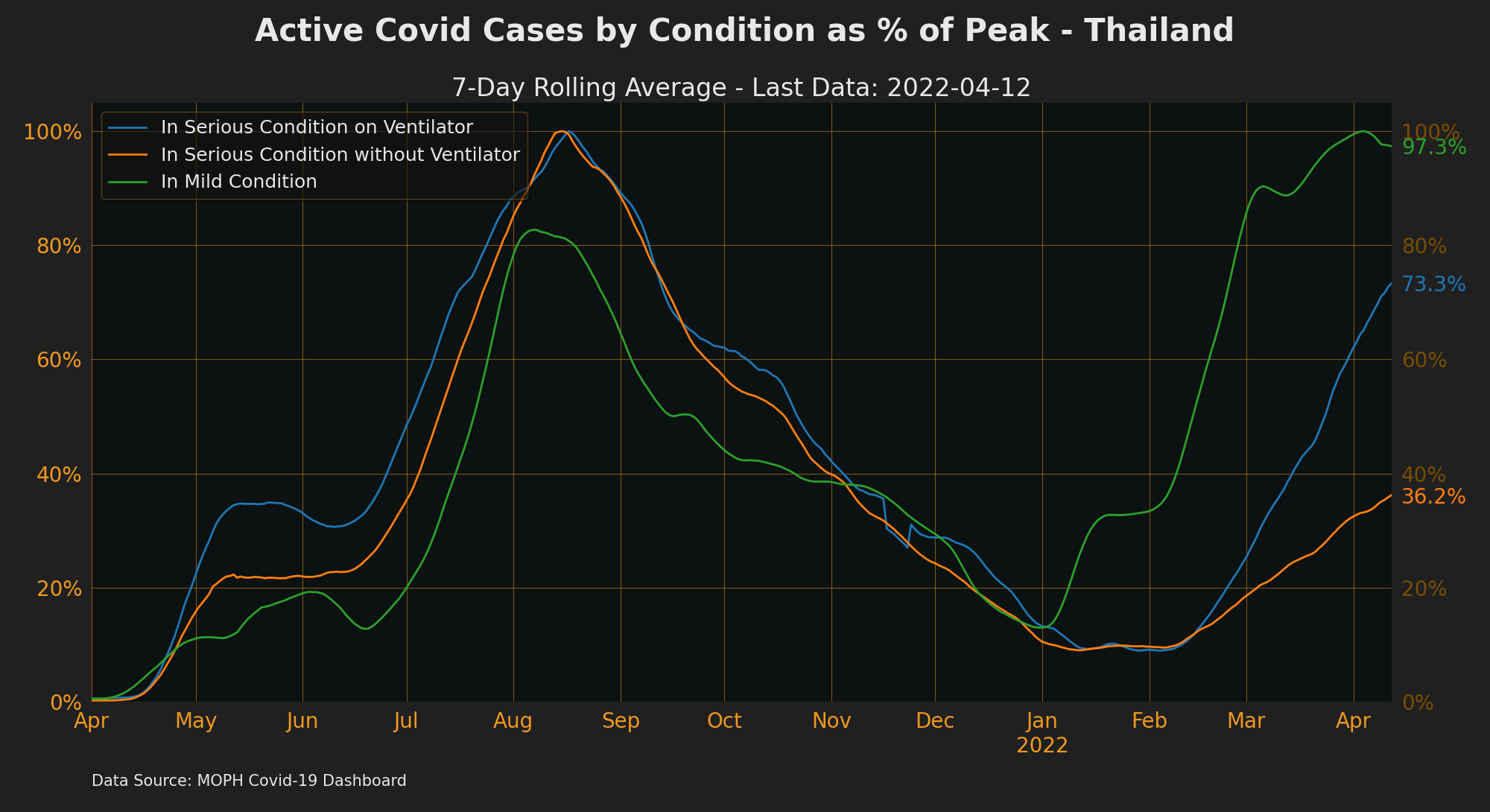
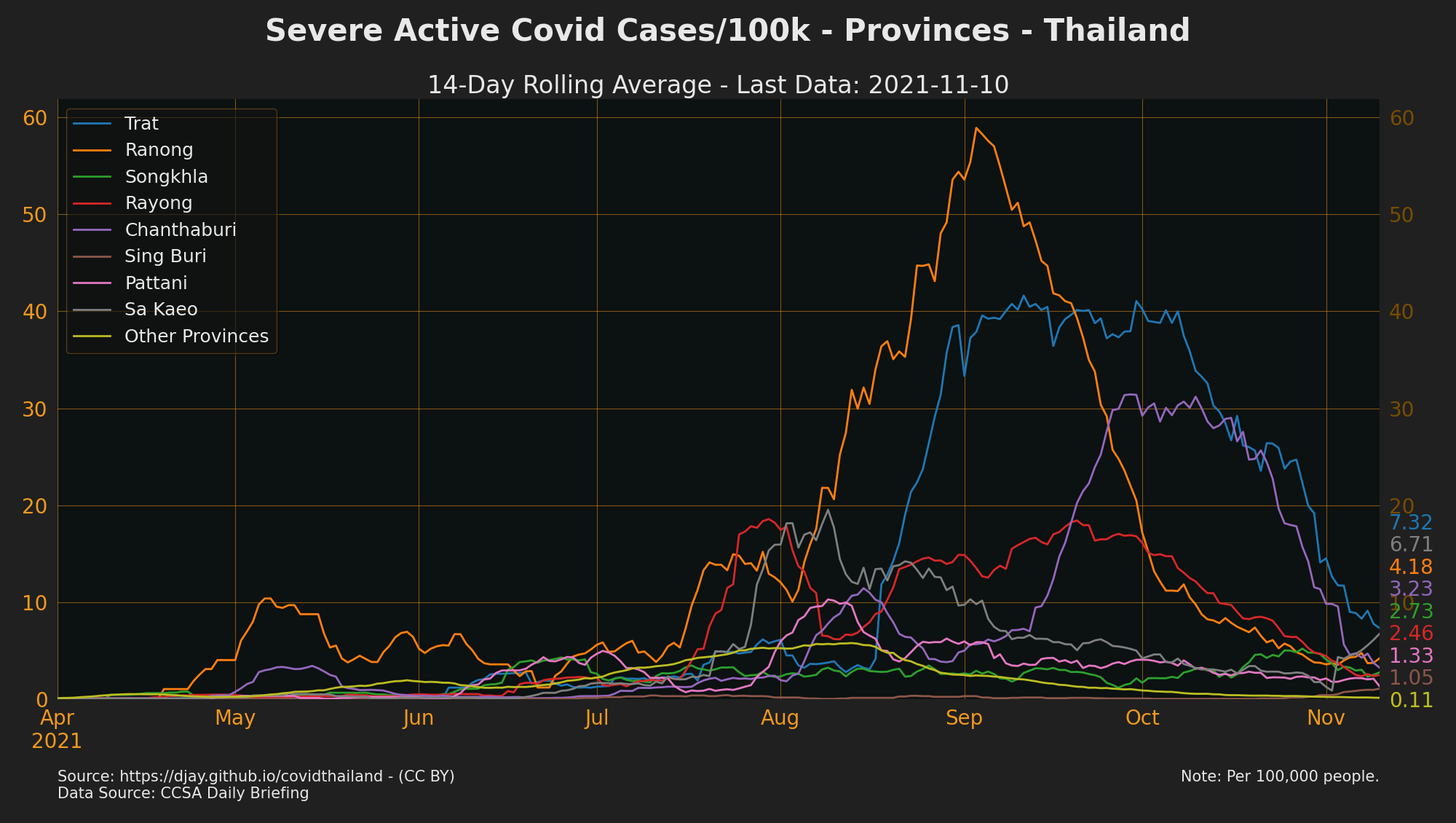
- Break down of active case status only available from 2020-04-24 onwards.
- Other Active Cases + ICU + Ventilator + Field hospitals = Hospitalised, which is everyone who is
confirmed (for 14days at least) - see Thailand Active Cases 2020-2021
- Source: CCSA Daily Briefing
){kind=link}
Deaths
COVID-19 Deaths
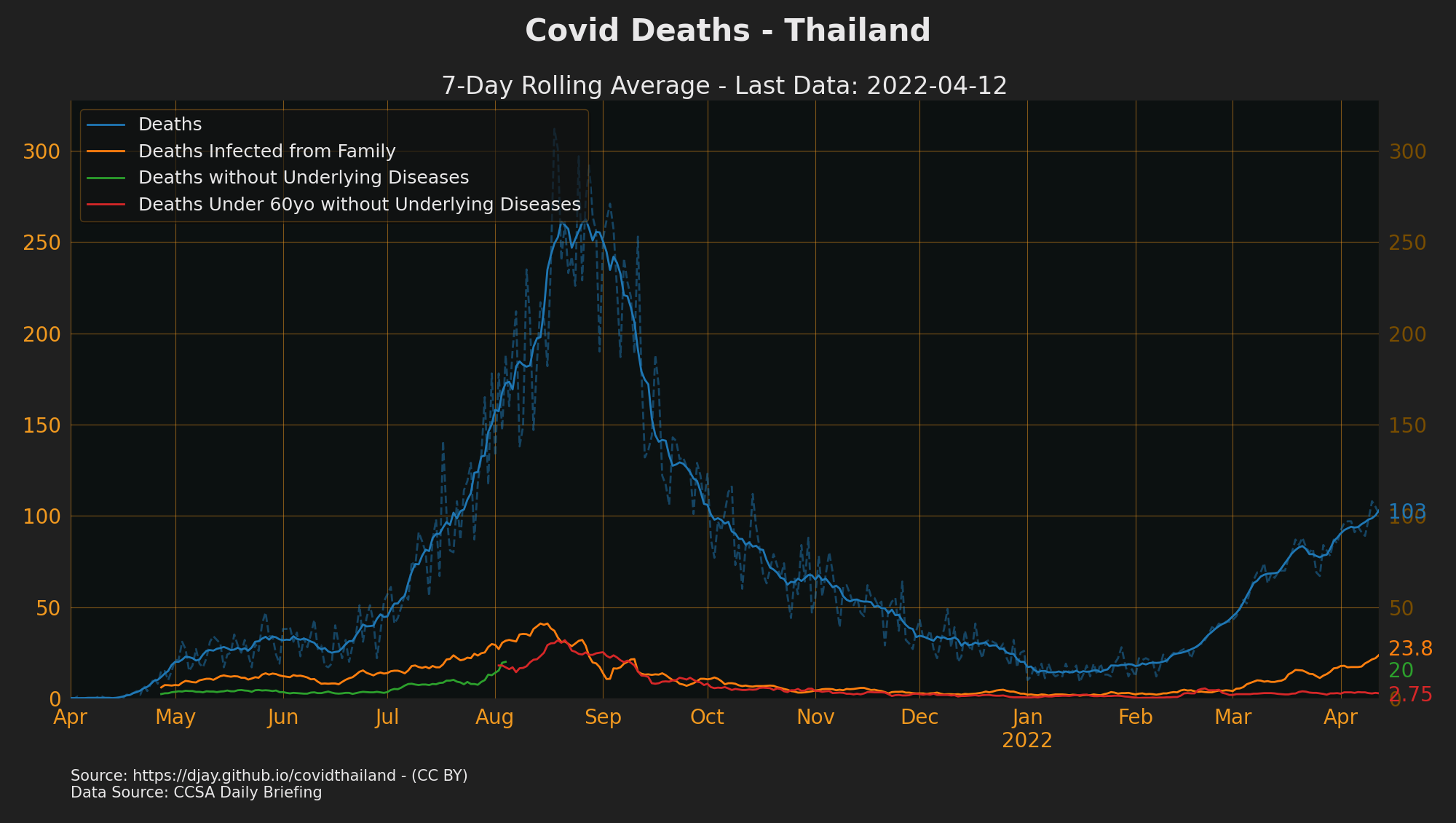
- source: CCSA Daily Briefing
COVID-19 Deaths by Health District
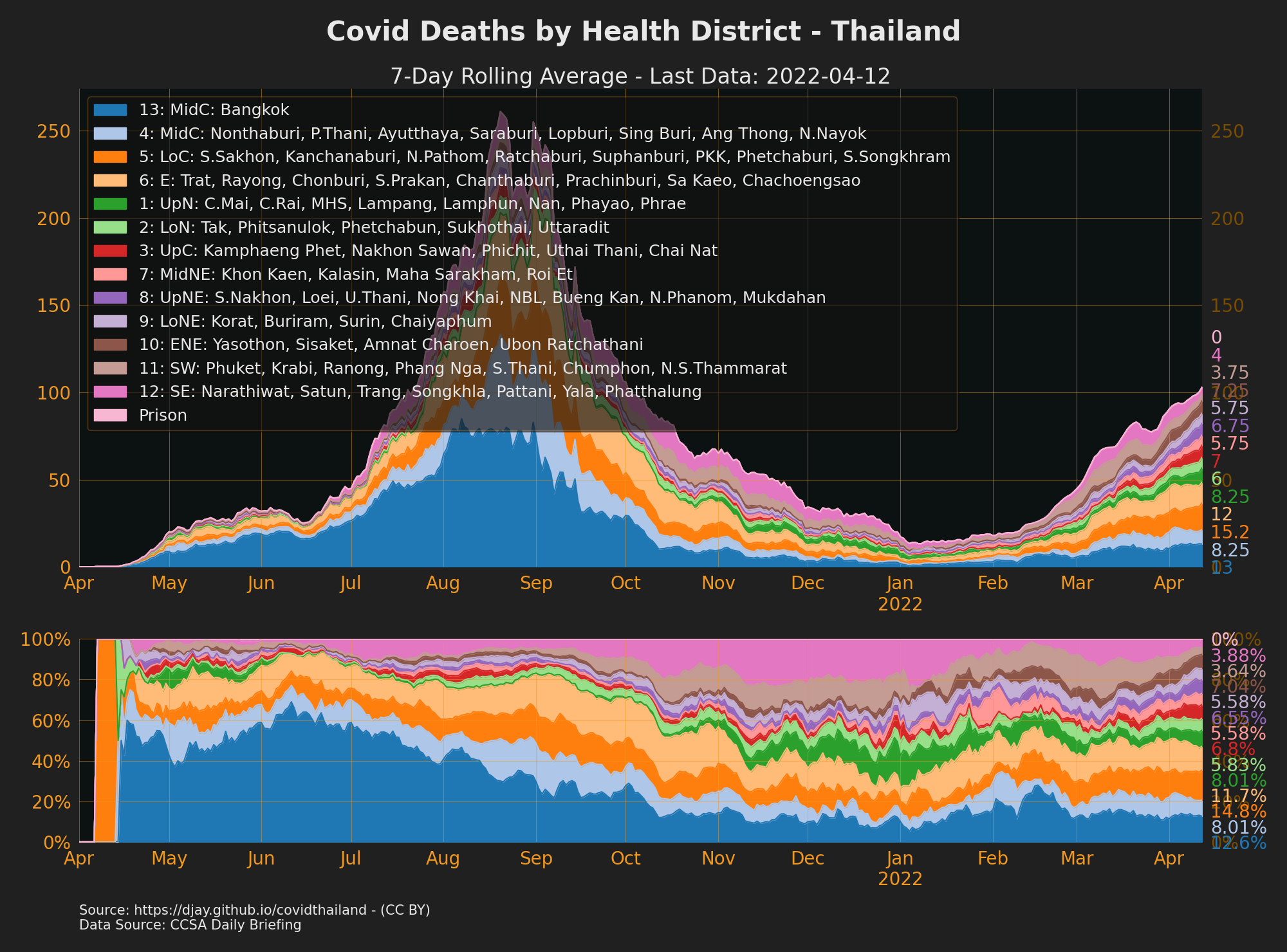
- source: CCSA Daily Briefing
COVID-19 Deaths Age Range
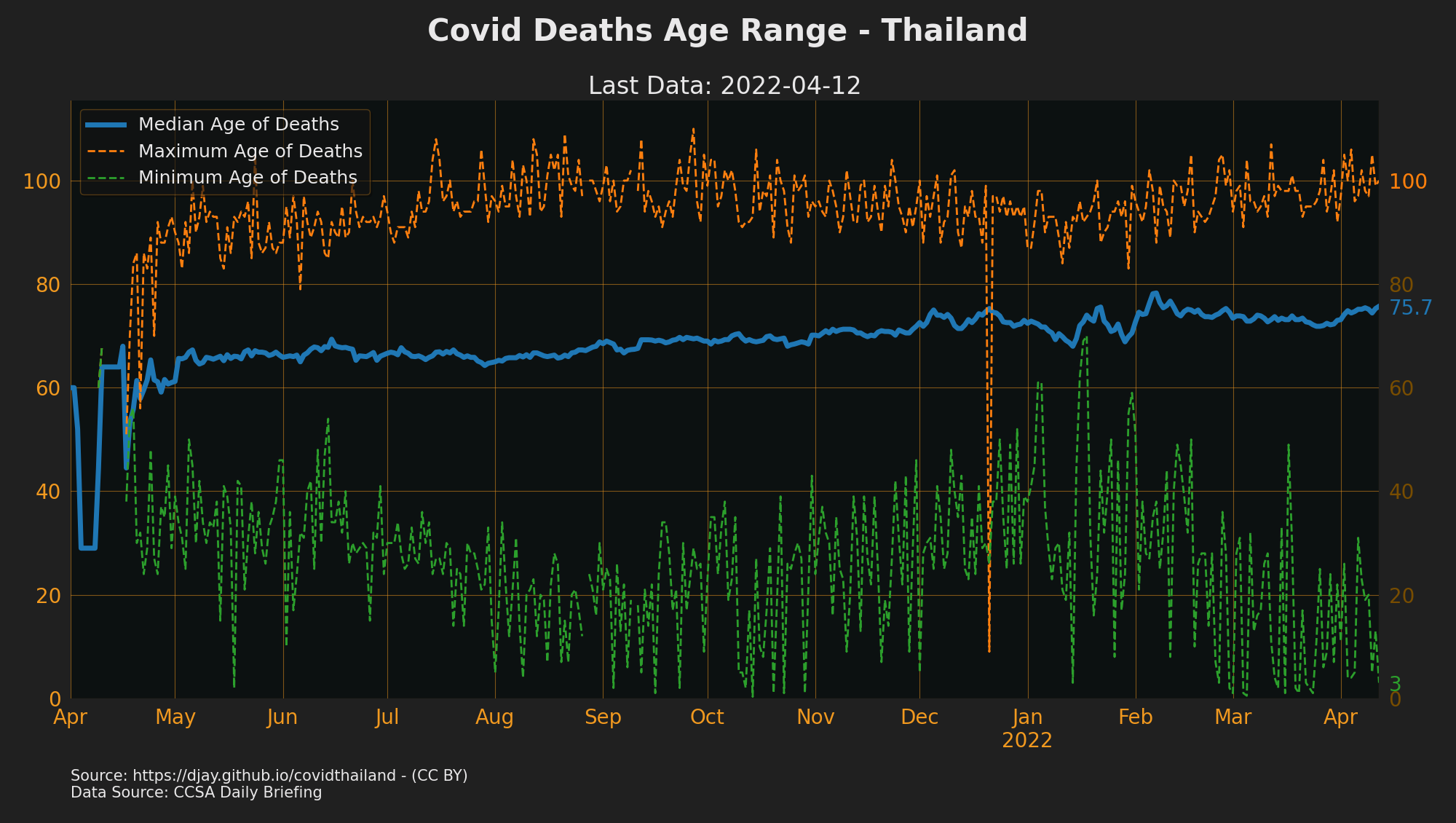
- Source: CCSA Daily Briefing
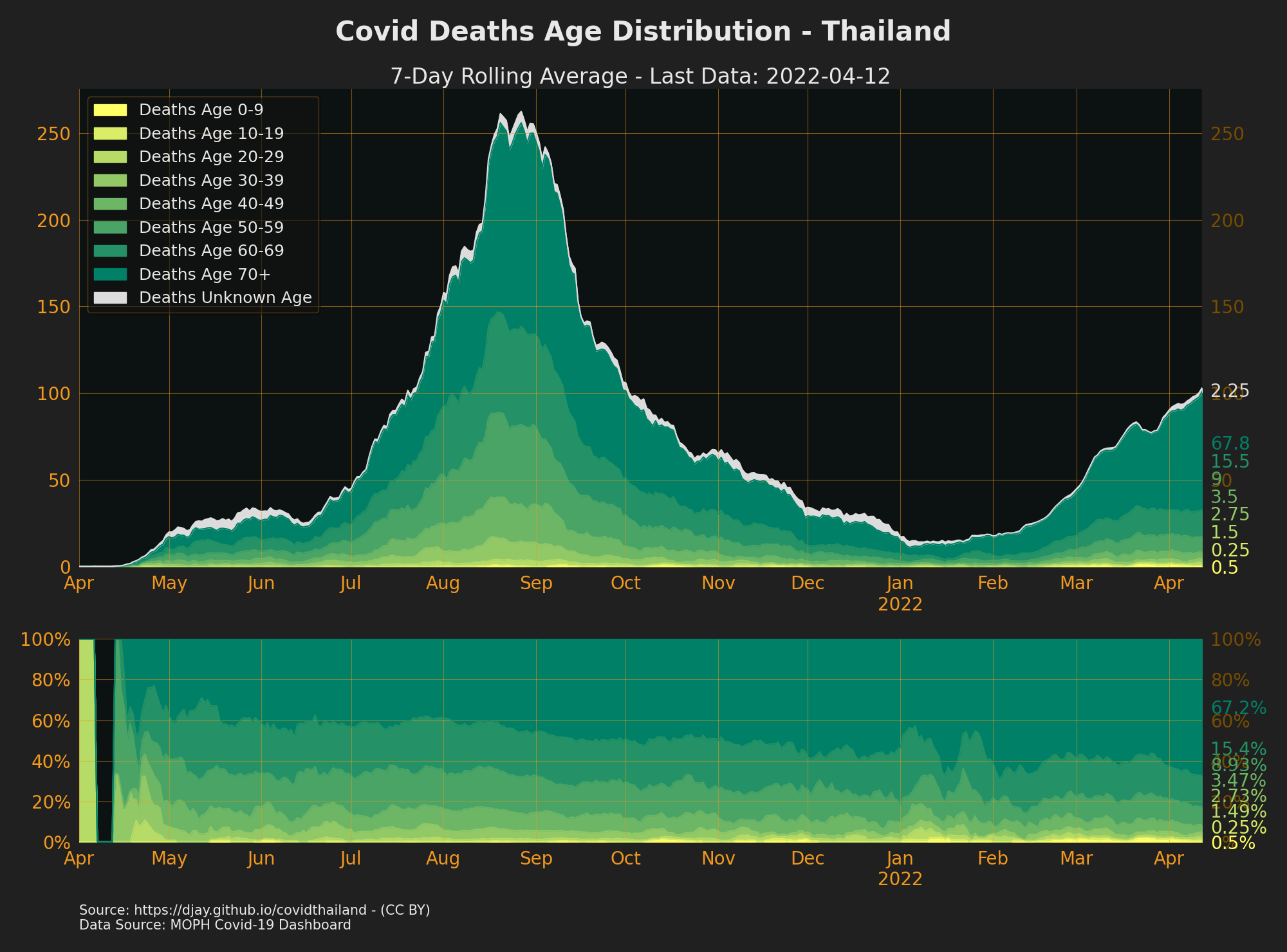
- Source: MOPH Covid-19 Dashboard
Testing
Positive Rate
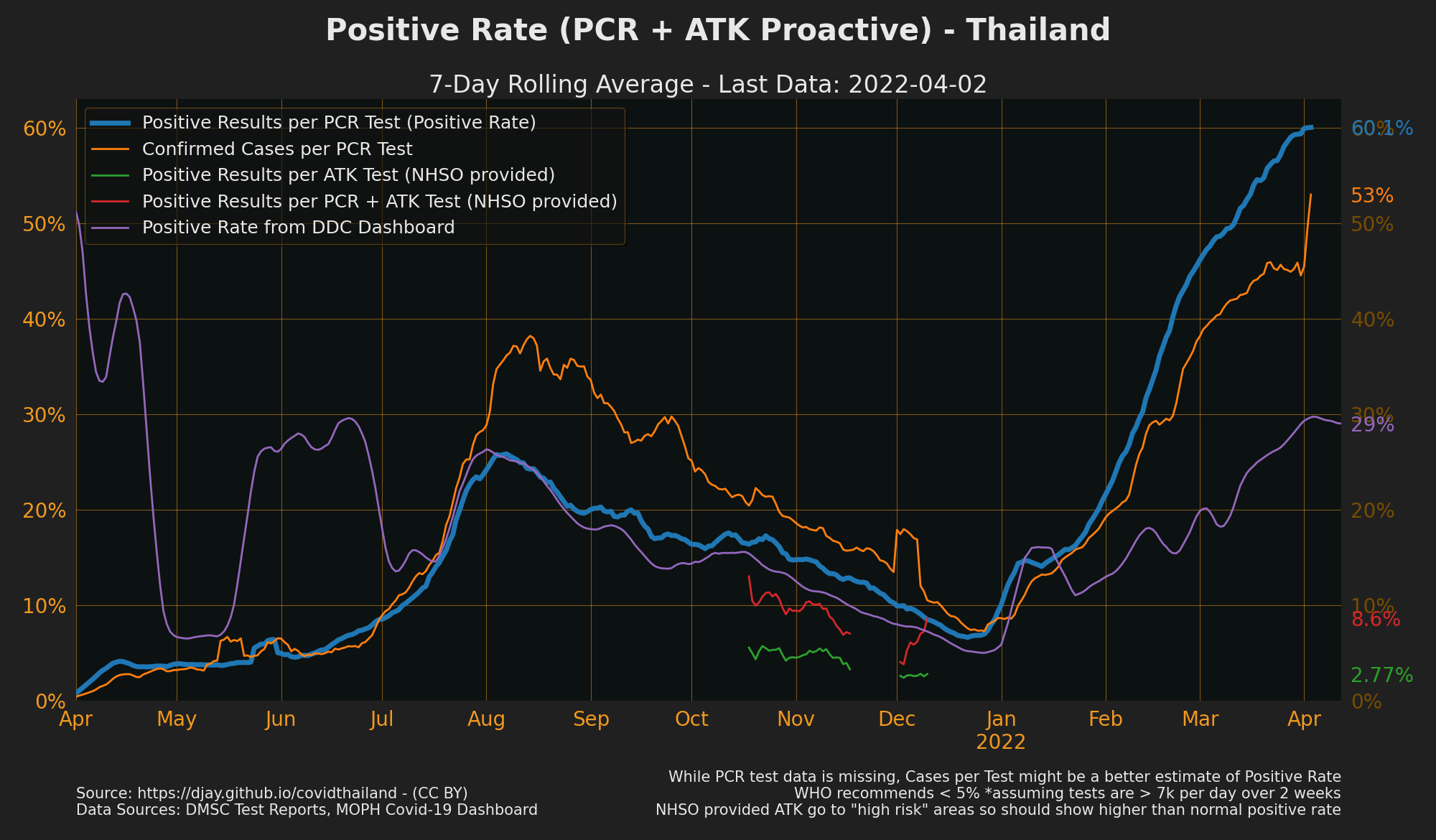
- NOTE Walkin Cases/3x PUI seems to give an estimate of positive rate (when cases are high), so it is included for when testing data is delayed. Note it is not the actual positive rate.
- Positive rate is little like fishing in a lake. If you get few nibbles each time you put your line in you can guess that there is few fish in the lake. Less positives per test, less infections likely in the population.
- WHO considers enough testing is happening if positive rate is under %5 rather than tests per population but only if 0.1% of the population is being tested per week (avg 7k tests per day for Thailand). Note this recommendation works best if everyone who might have COVID-19 is equally likely to get tested and there are reasons why this might not be the case in Thailand.
- It’s likely Thailand excludes some test data so there could be more tests than this data shows. Excluding proactive tests from positive rate is perhaps better for comparison with other countries they are less random and more likely to be positive as its testing known clusters.
- Rapid antigen tests are not included in the test data, or in confirmed case numbers (unless they also had a positive PCR test). This is similar to most countries however some like UK count antigen tests in both tests and confirmed cases.
- This positive rate is based on DMSC: Thailand Laboratory testing data. In the Daily MOPH Situation Reports is a number labelled
Total number of laboratory tests.Total number of laboratory testsis mislabelled and is exactly the same as the PUI number. - see also Positive Rate: Full year, Tests per Case Graph (Positive rate inverted) could be easier to understand.
- Sources: DMSC: Thailand Laboratory testing data, Daily situation Reports
{kind=link}
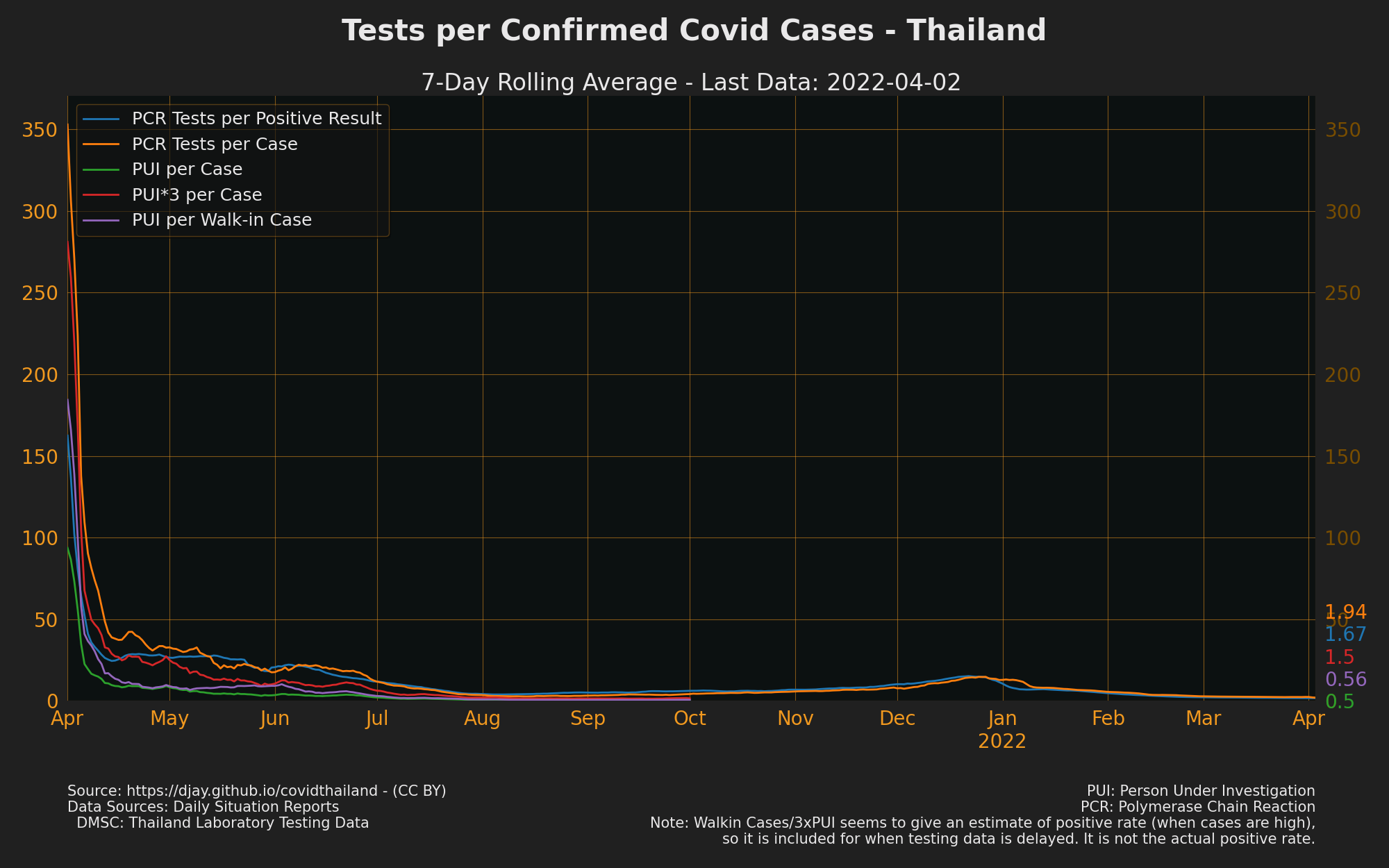{kind=link}
PCR Tests in Thailand by day
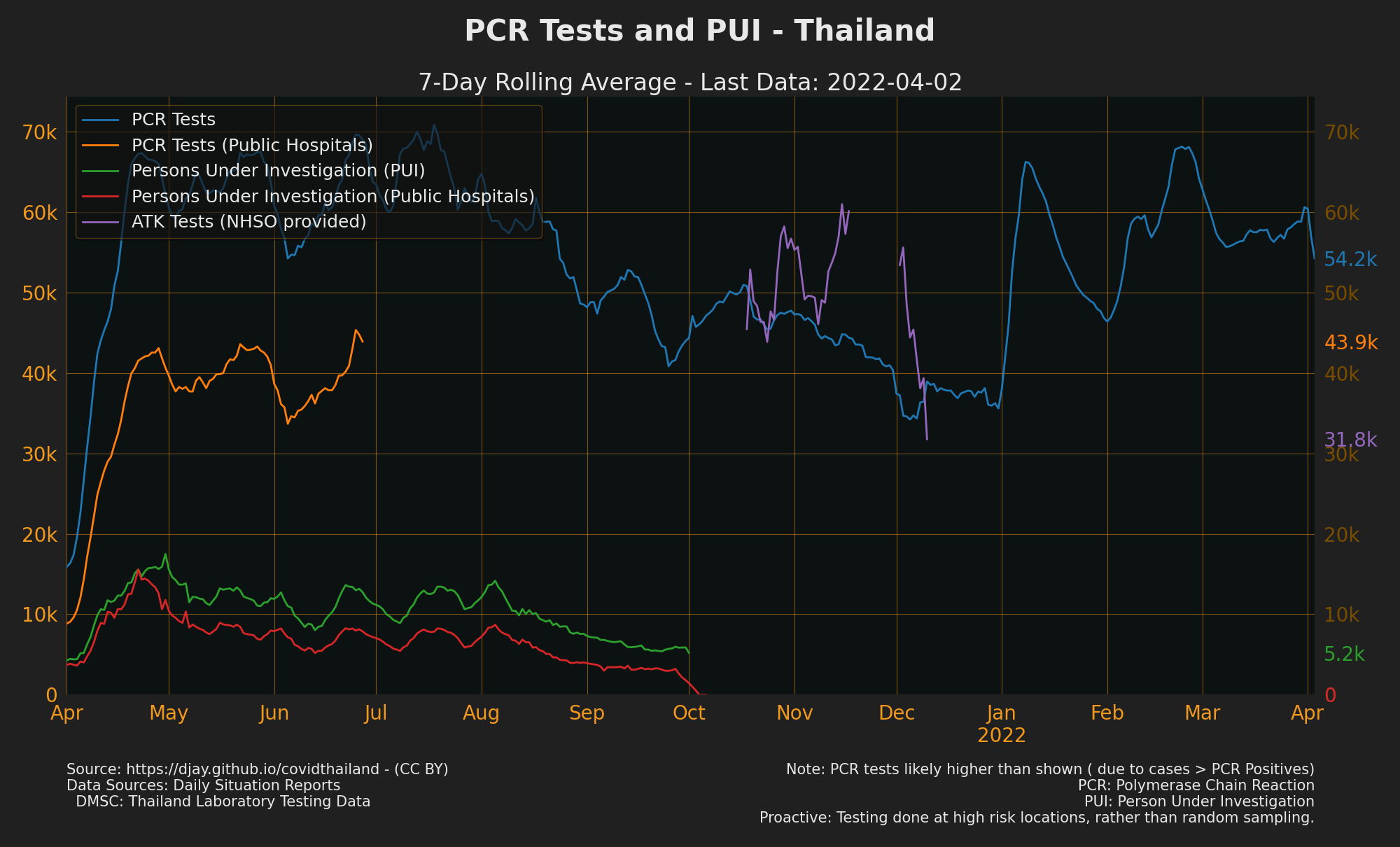
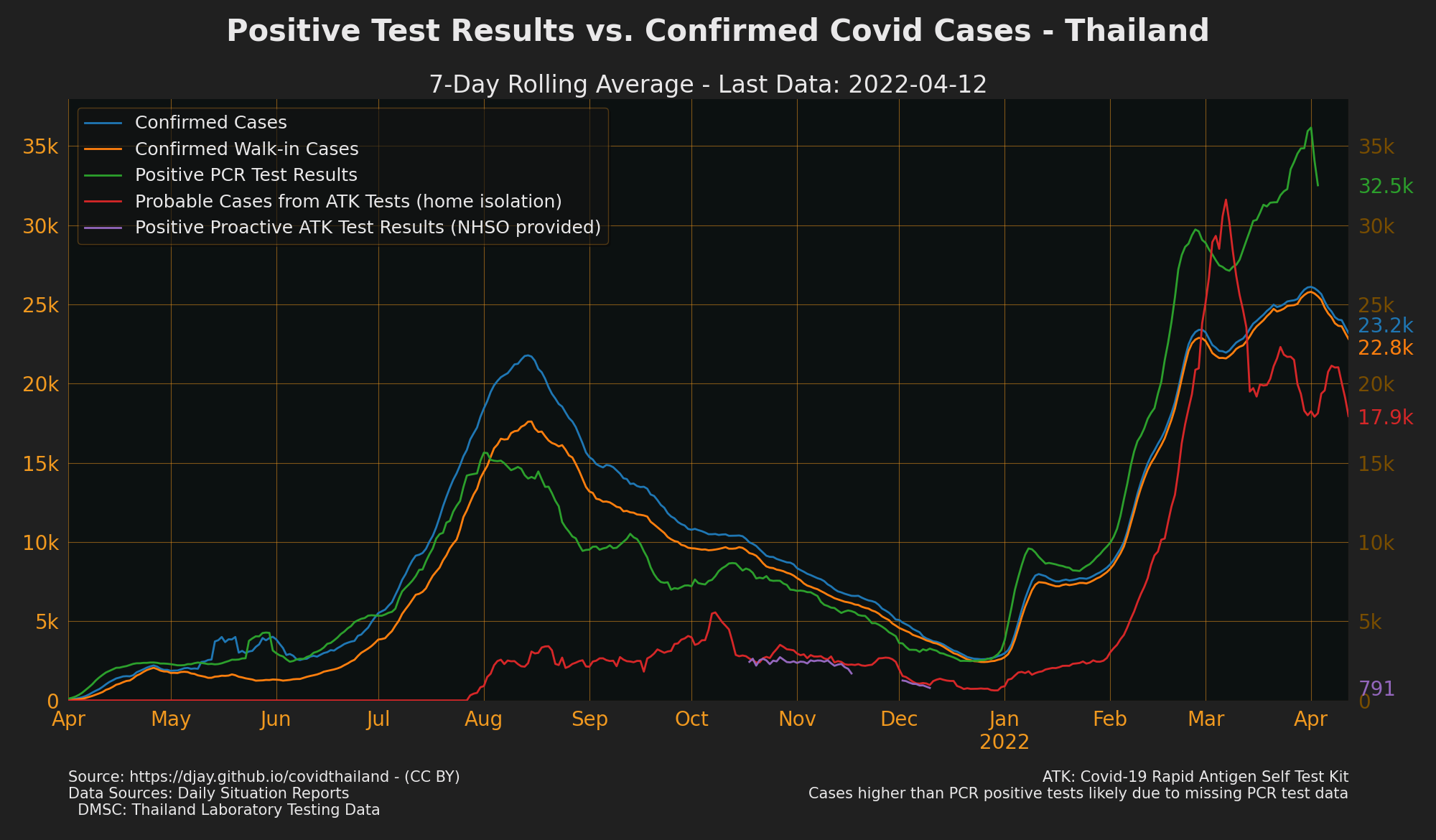
- There are more confirmed cases than positives in Thailand’s testing data, this could be for various reasons but could make the positive rate lower.
- Sources: Daily situation Reports, DMSC: Thailand Laboratory testing data
PCR Tests by Health District
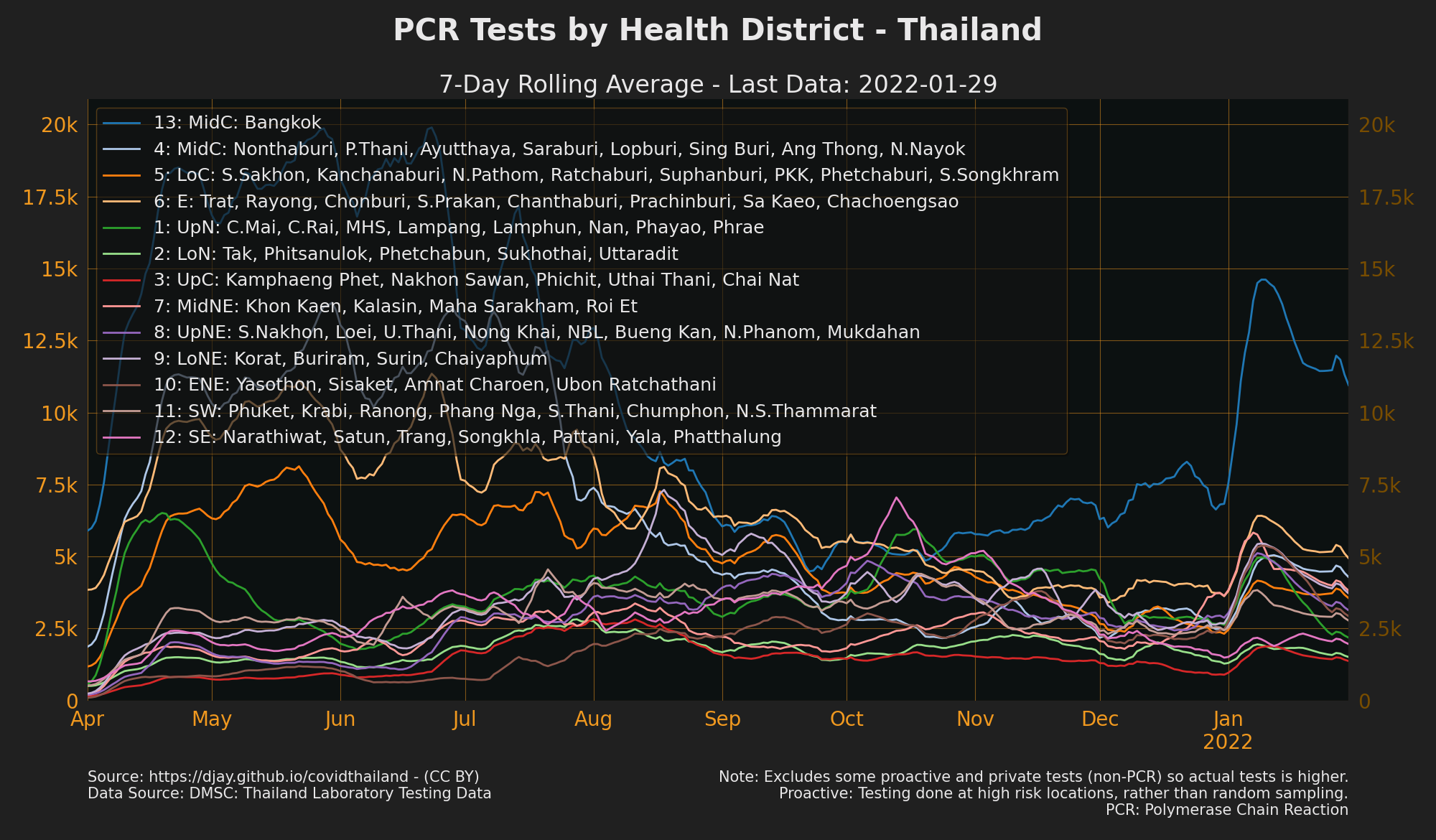
- Tests by health area: Full Year
- NOTE Excludes some proactive tests (non-PCR) so actual tests is higher
- Source: DMSC: Thailand Laboratory testing data
{kind=link}
Positive Rate by Province
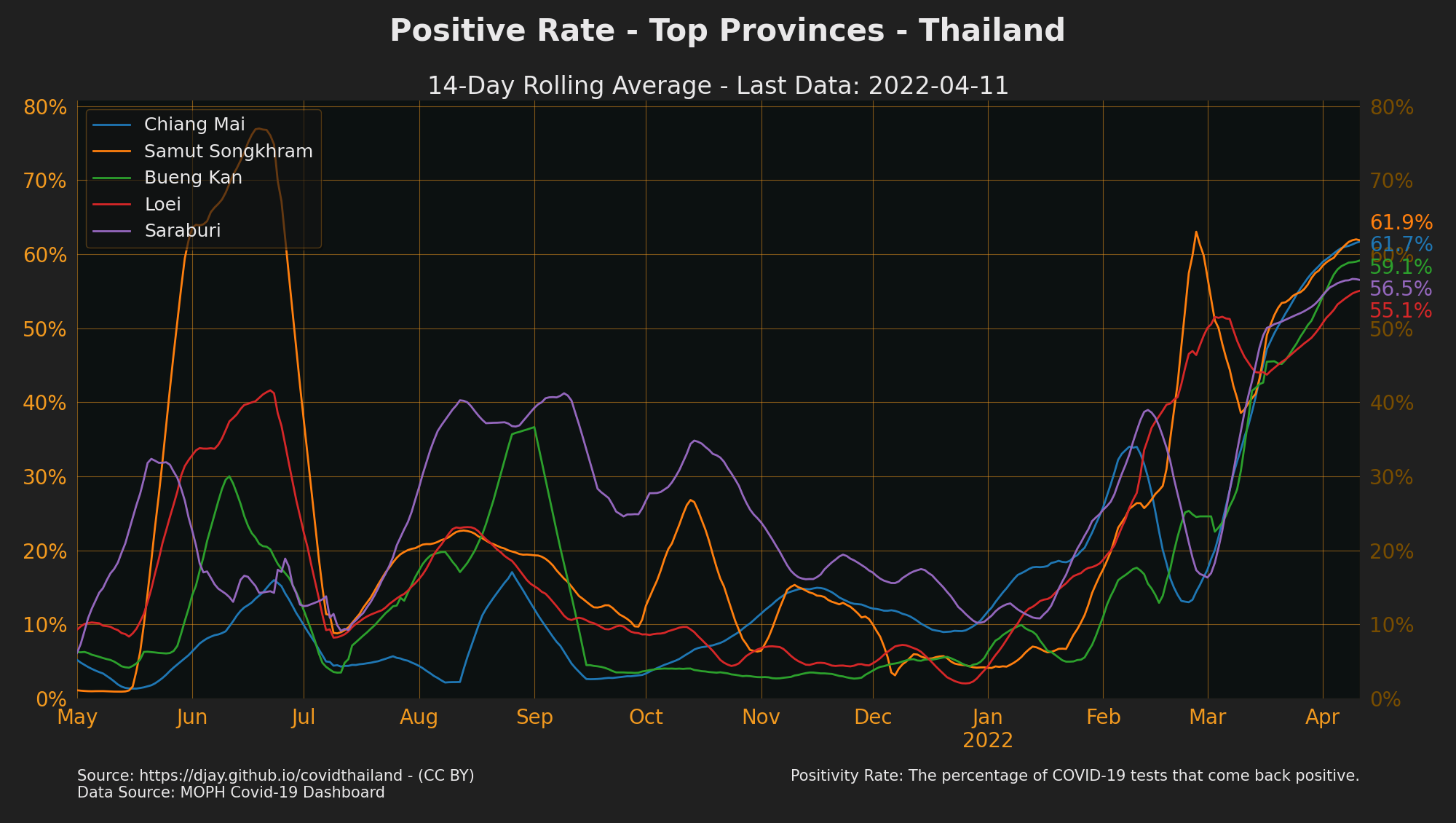

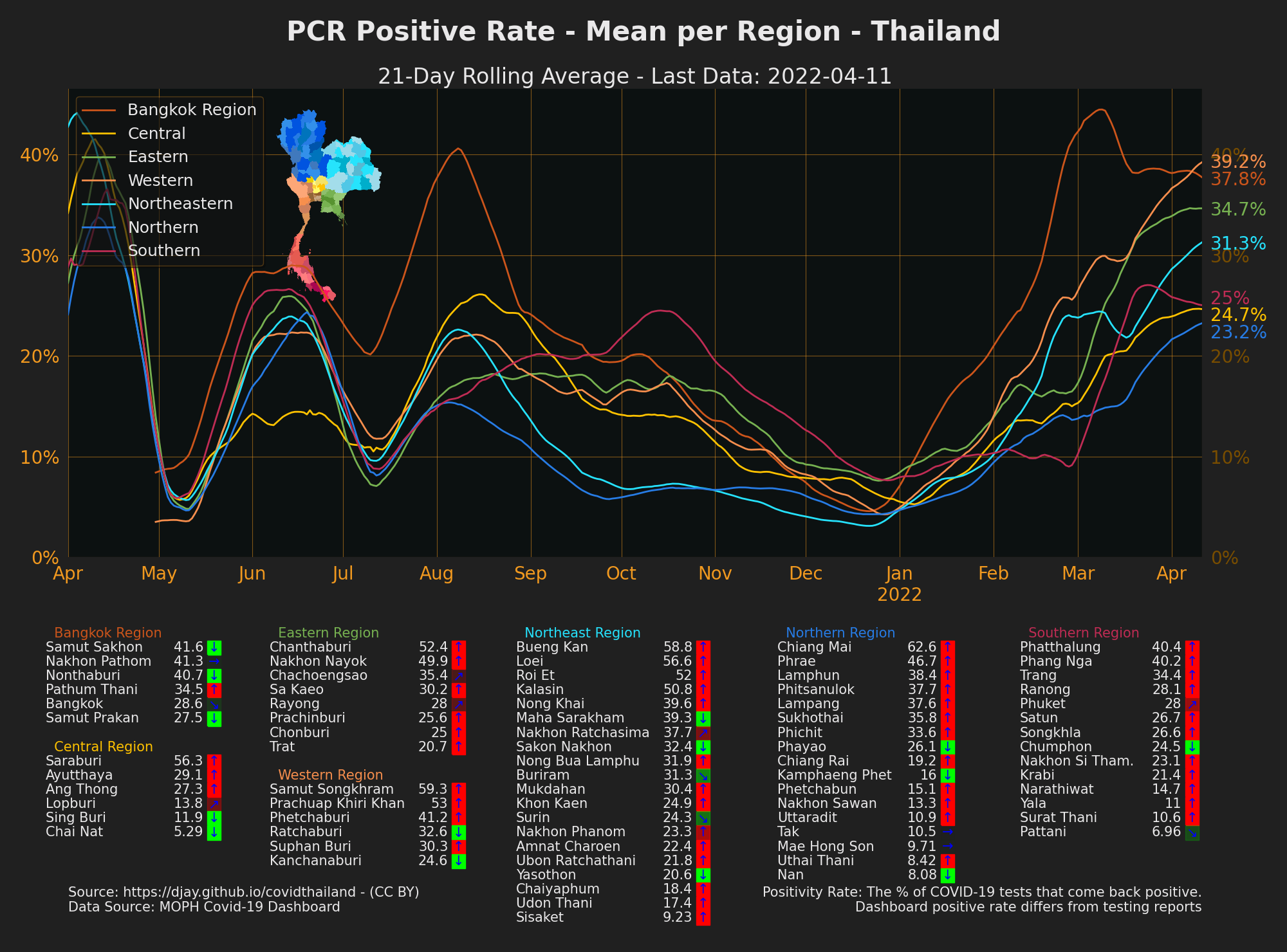
- Source: MOPH Covid-19 Dashboard
Vaccinations
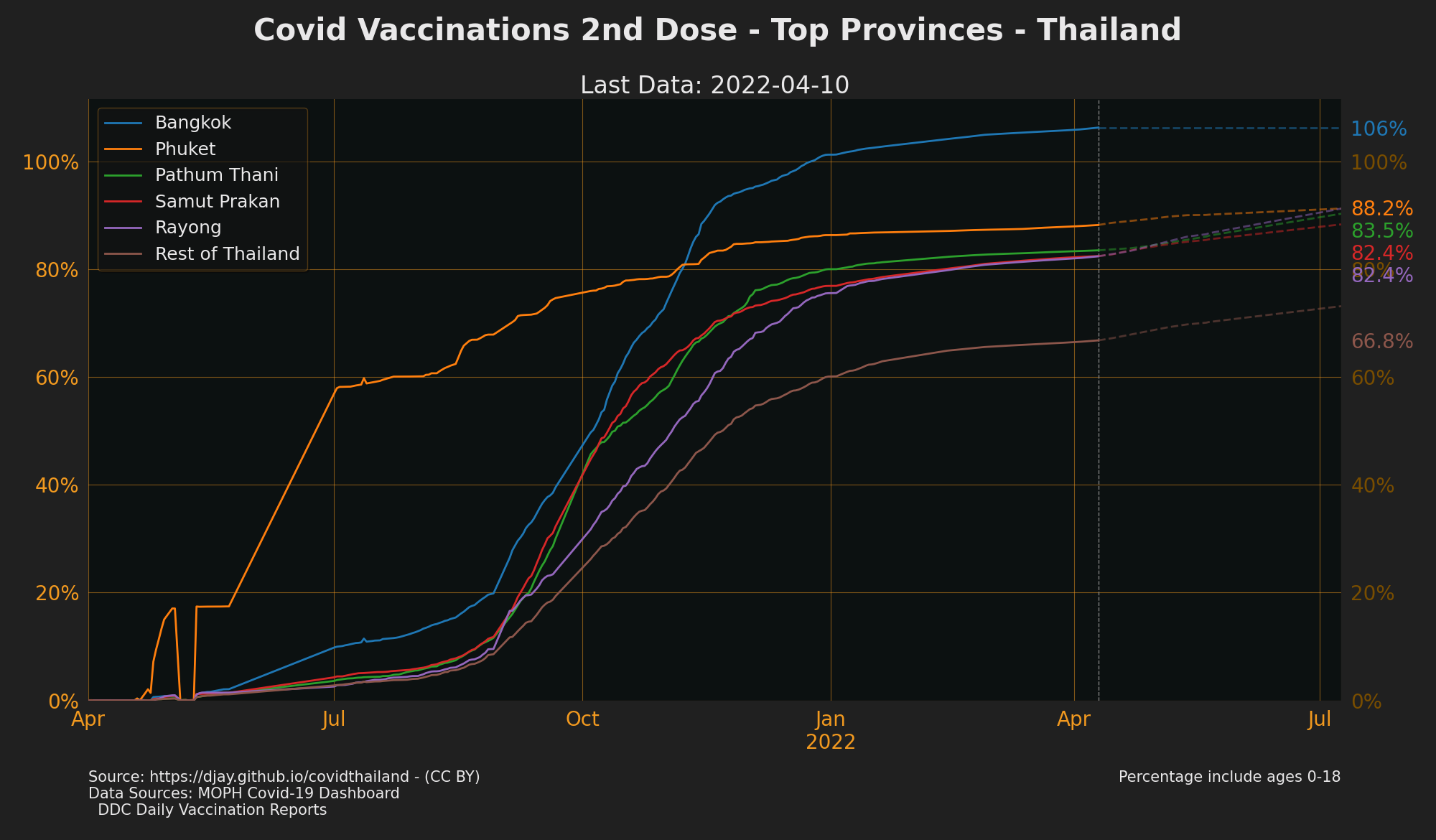
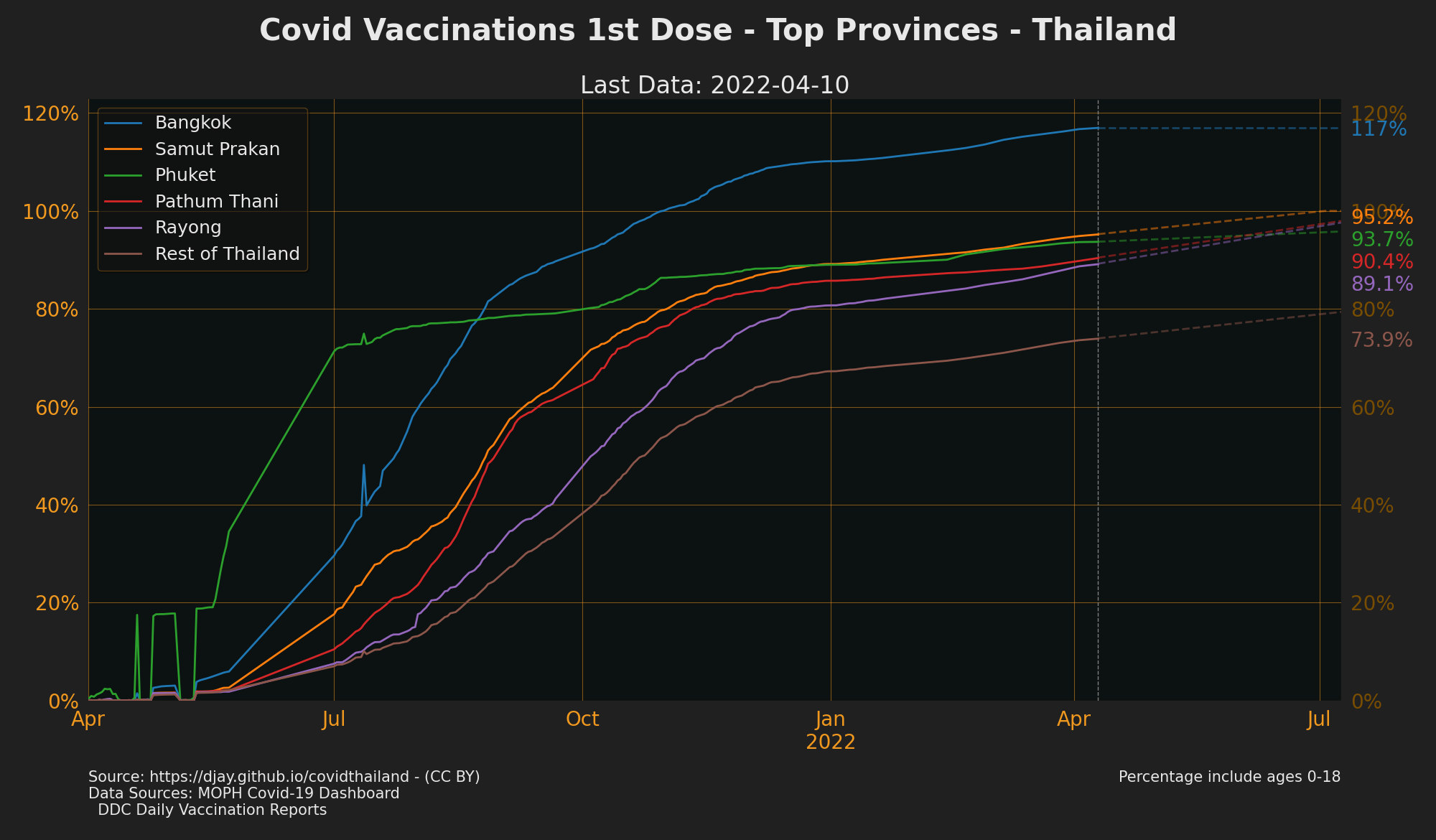
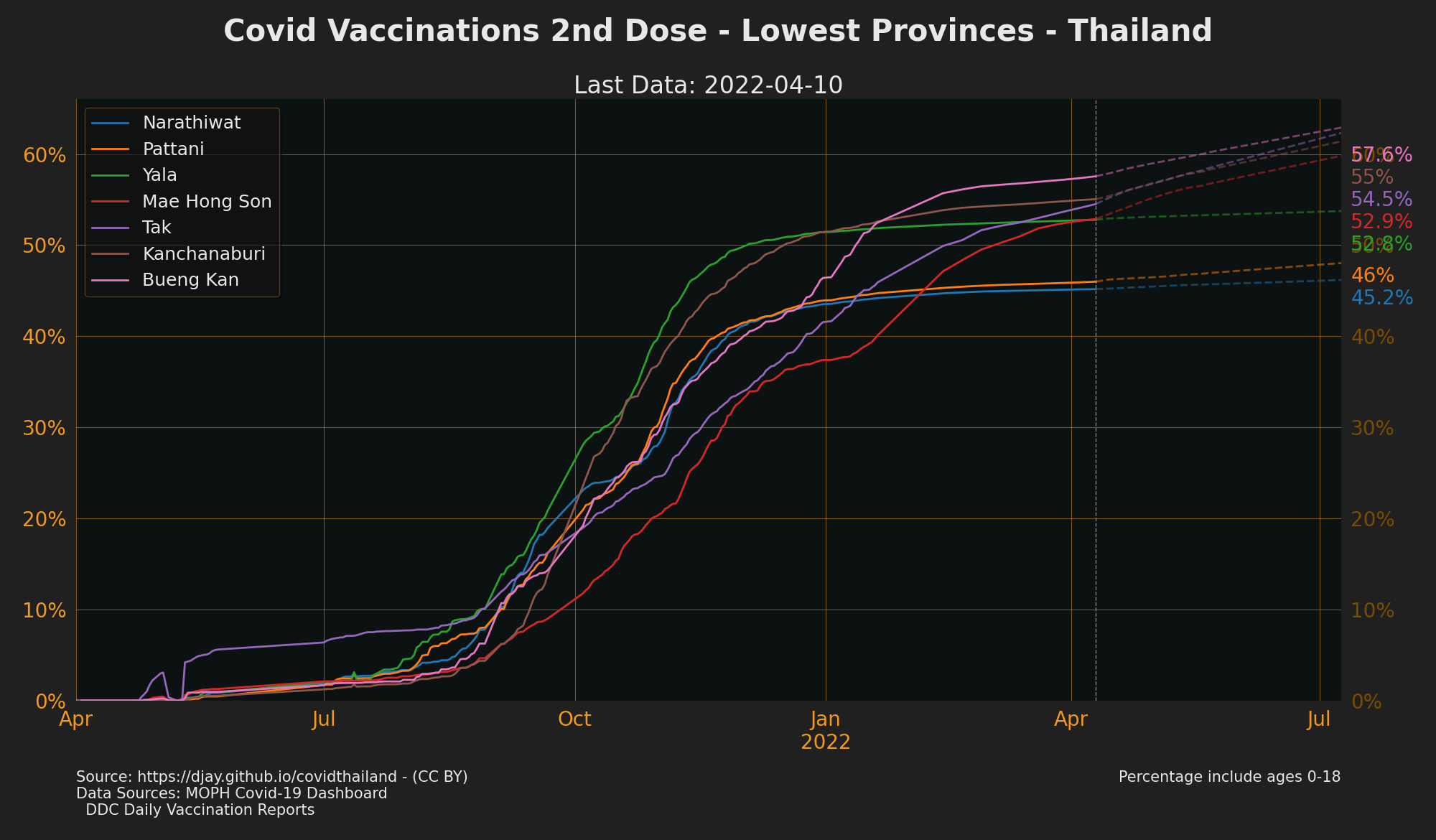
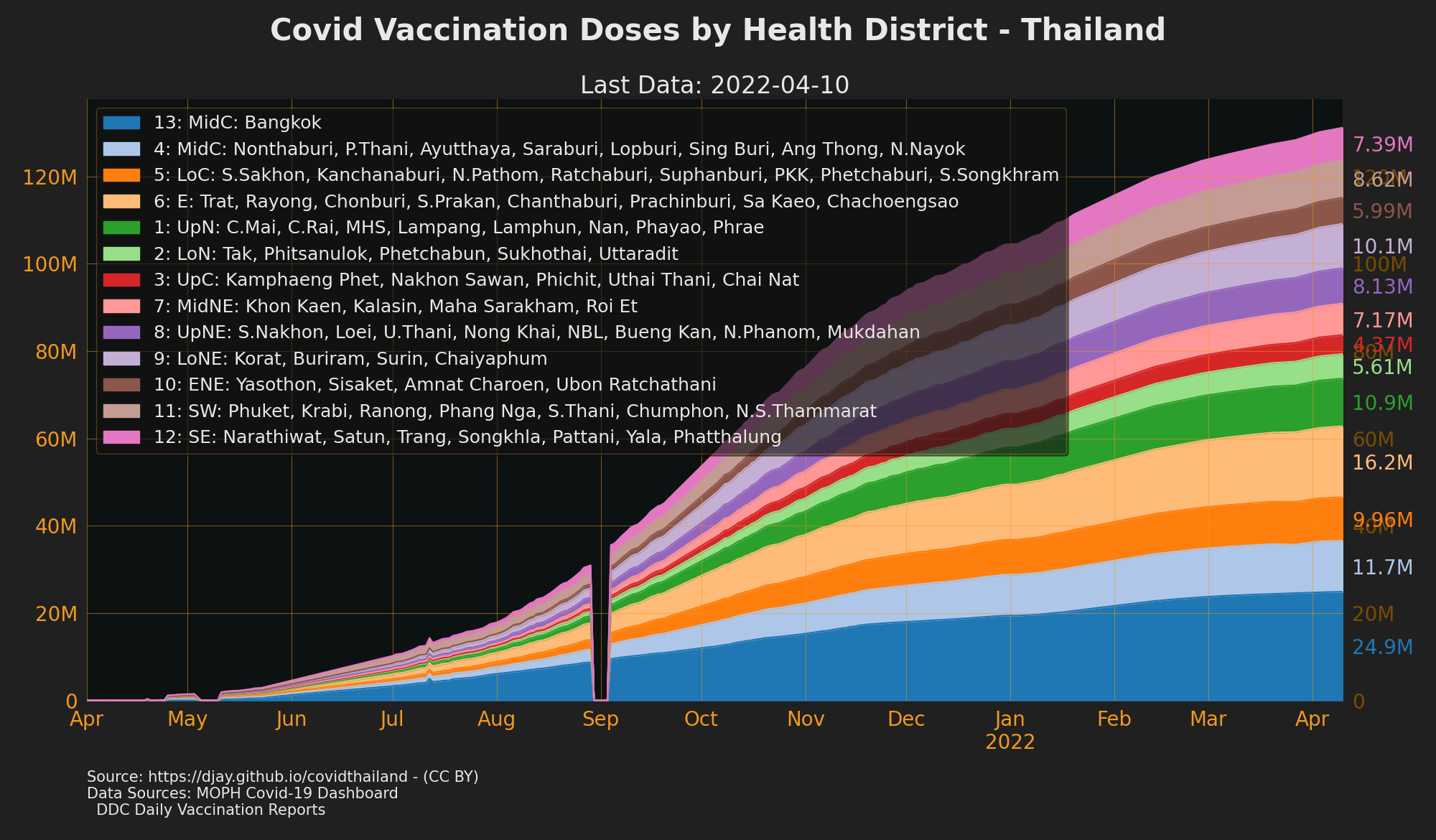
Vaccinations by Priority Groups
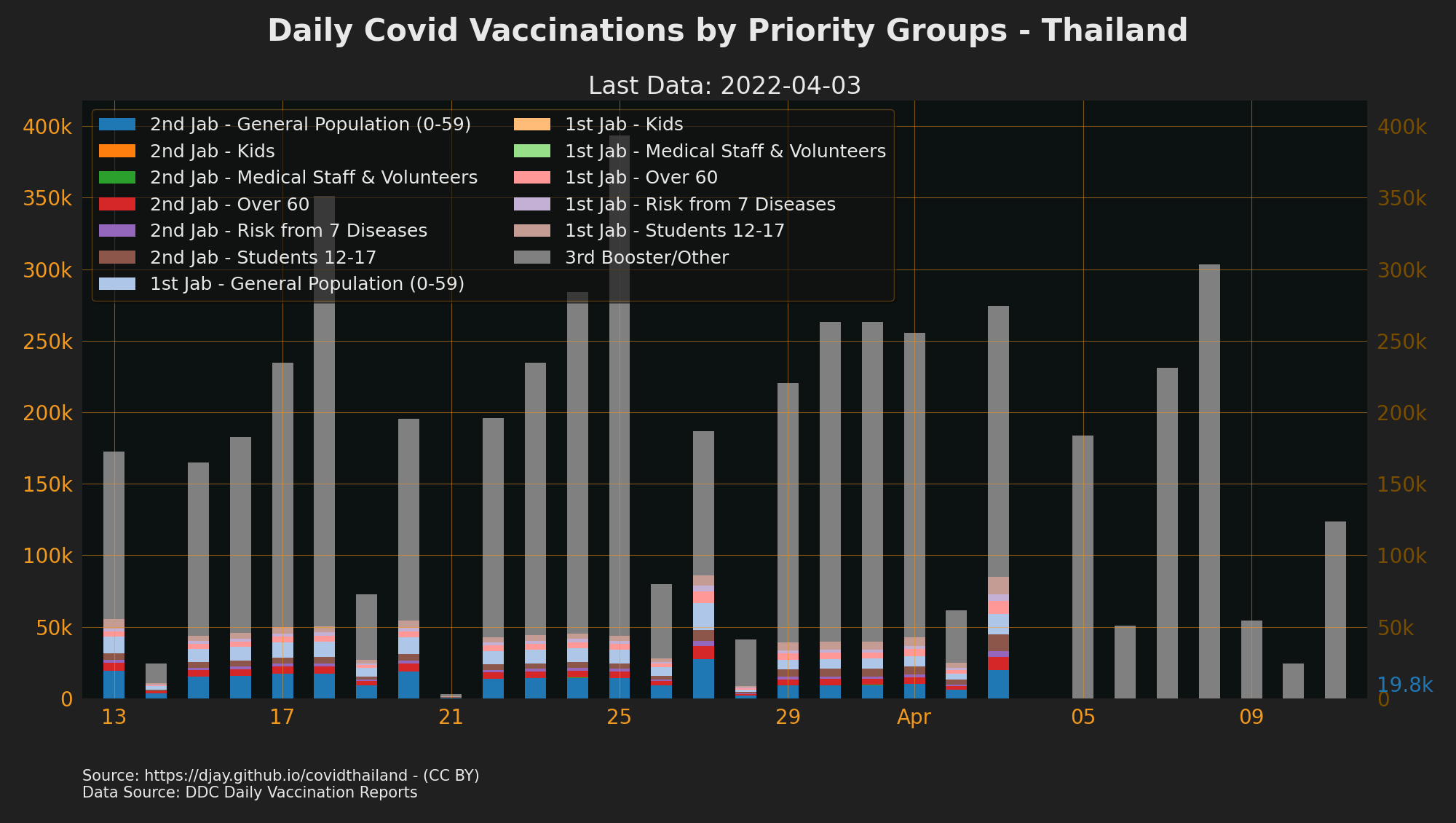
- Source: DDC Daily Vaccination Reports
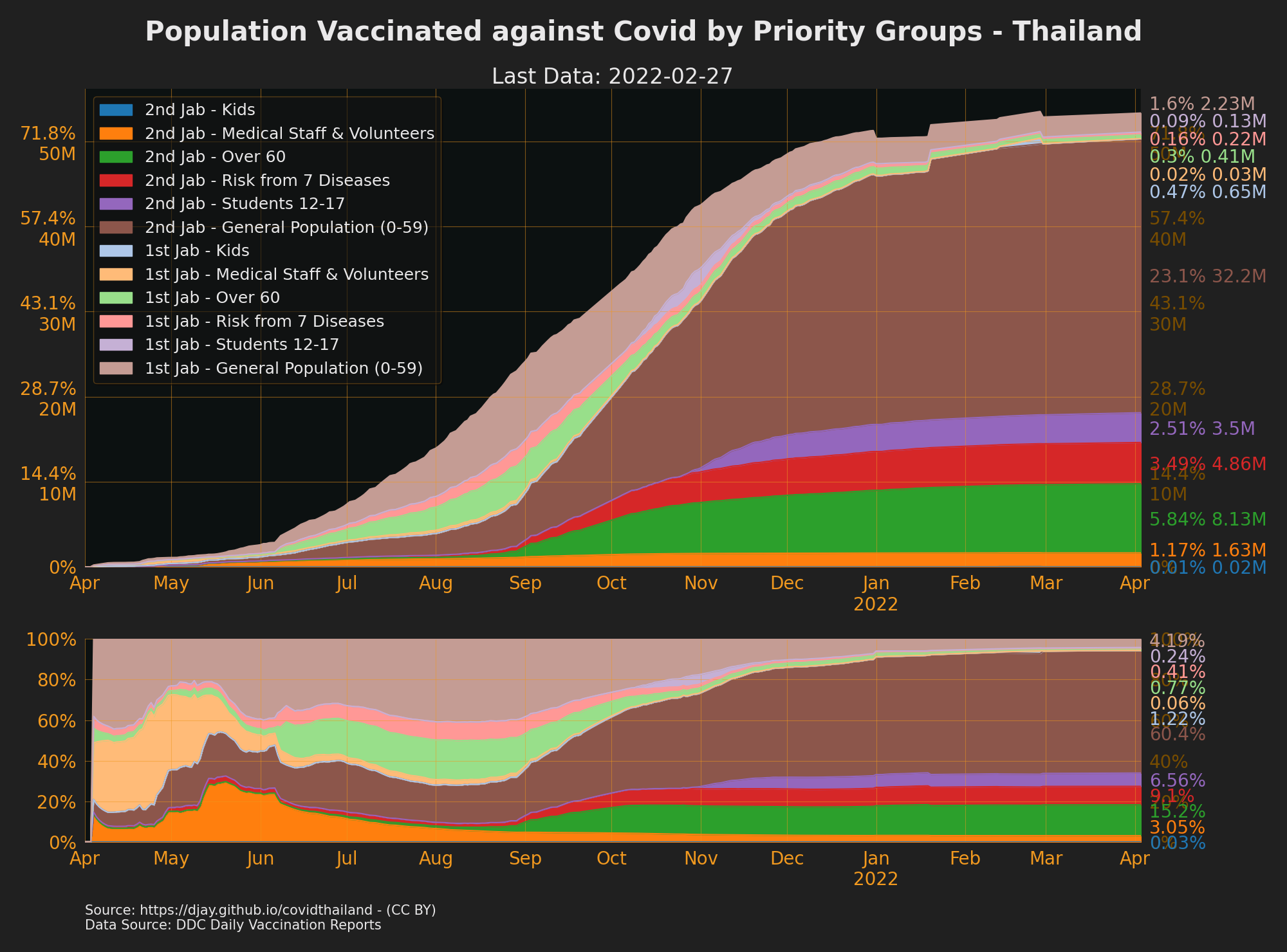
- Source: DDC Daily Vaccination Reports
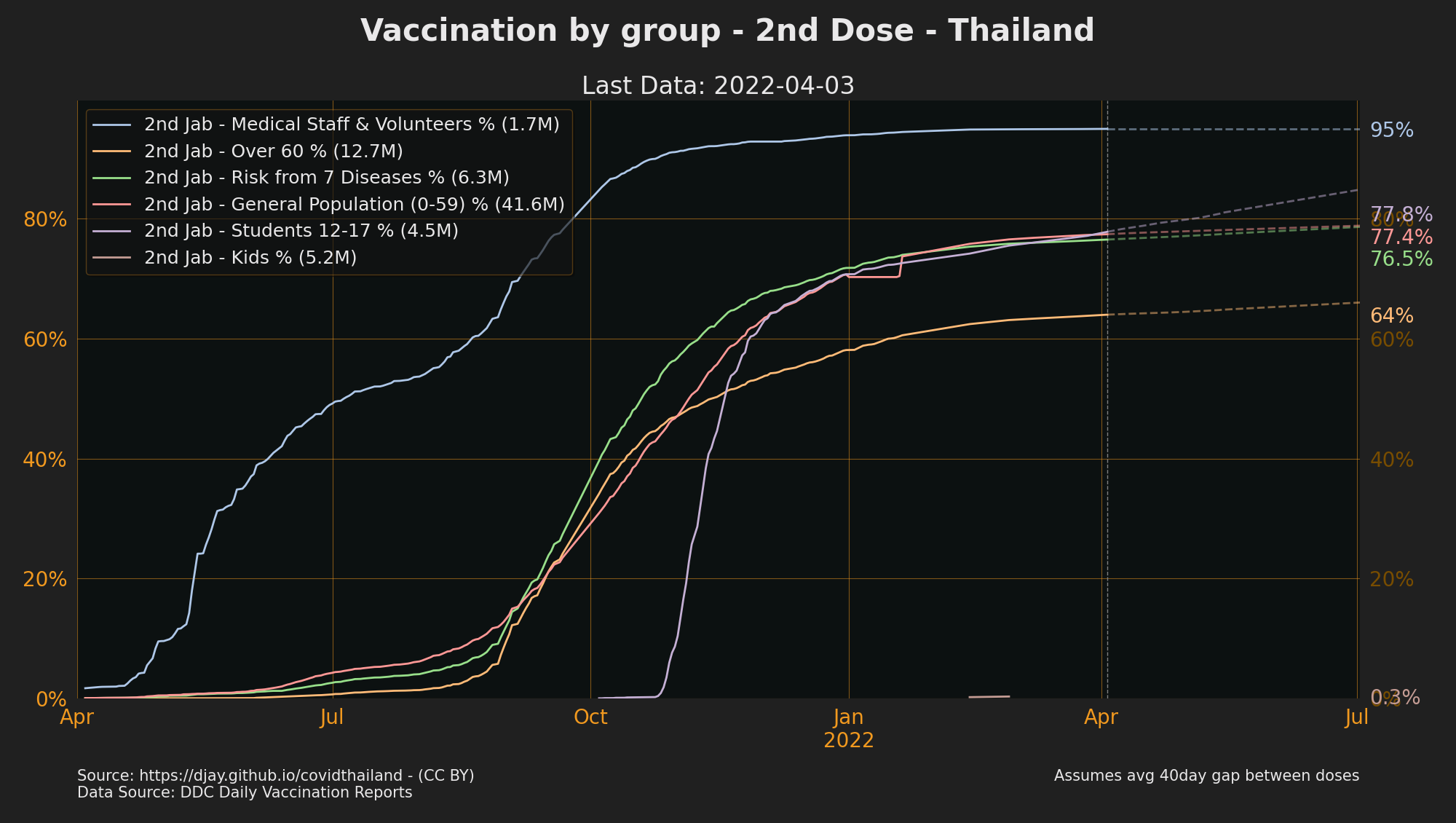
- Source: DDC Daily Vaccination Reports

- Source: DDC Daily Vaccination Reports

Excess Deaths
Shows Deaths from all causes in comparison to the min, max and mean of Deaths from the 5 years pre-pandemic.
- Note: there are many possible factors alter deaths up or down other than uncounted Covid Deaths
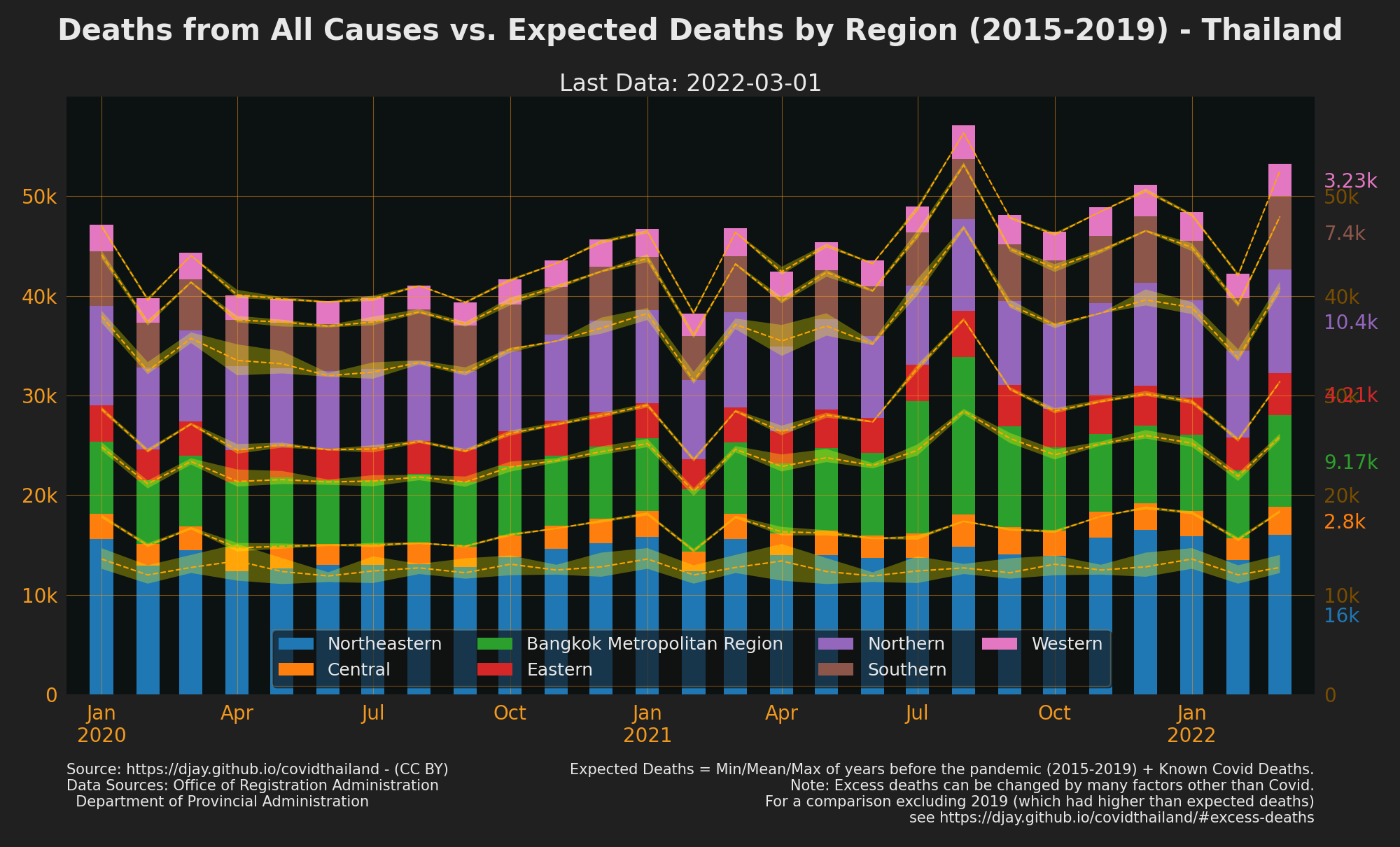
{kind=link}

{kind=link}
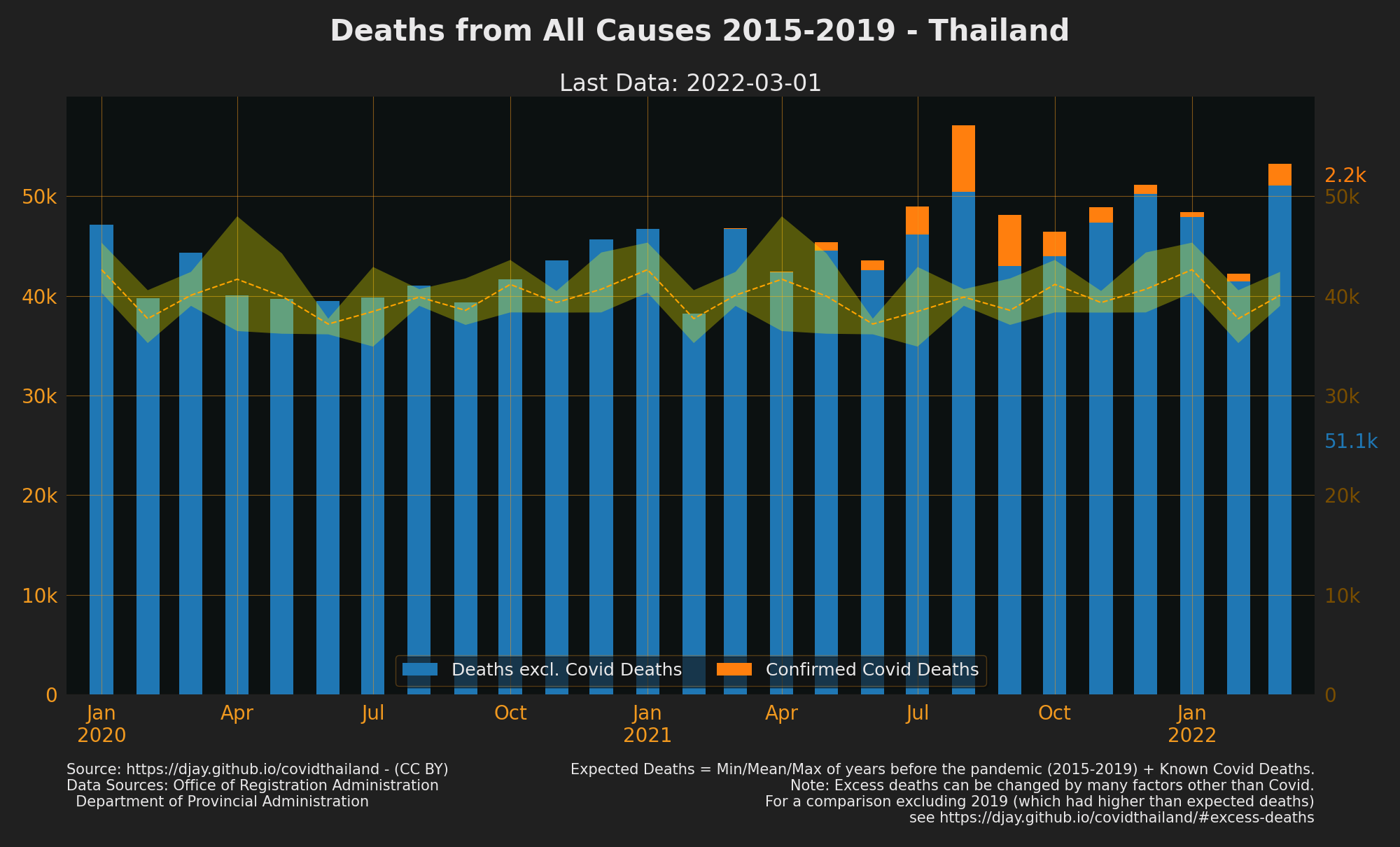
{kind=link}
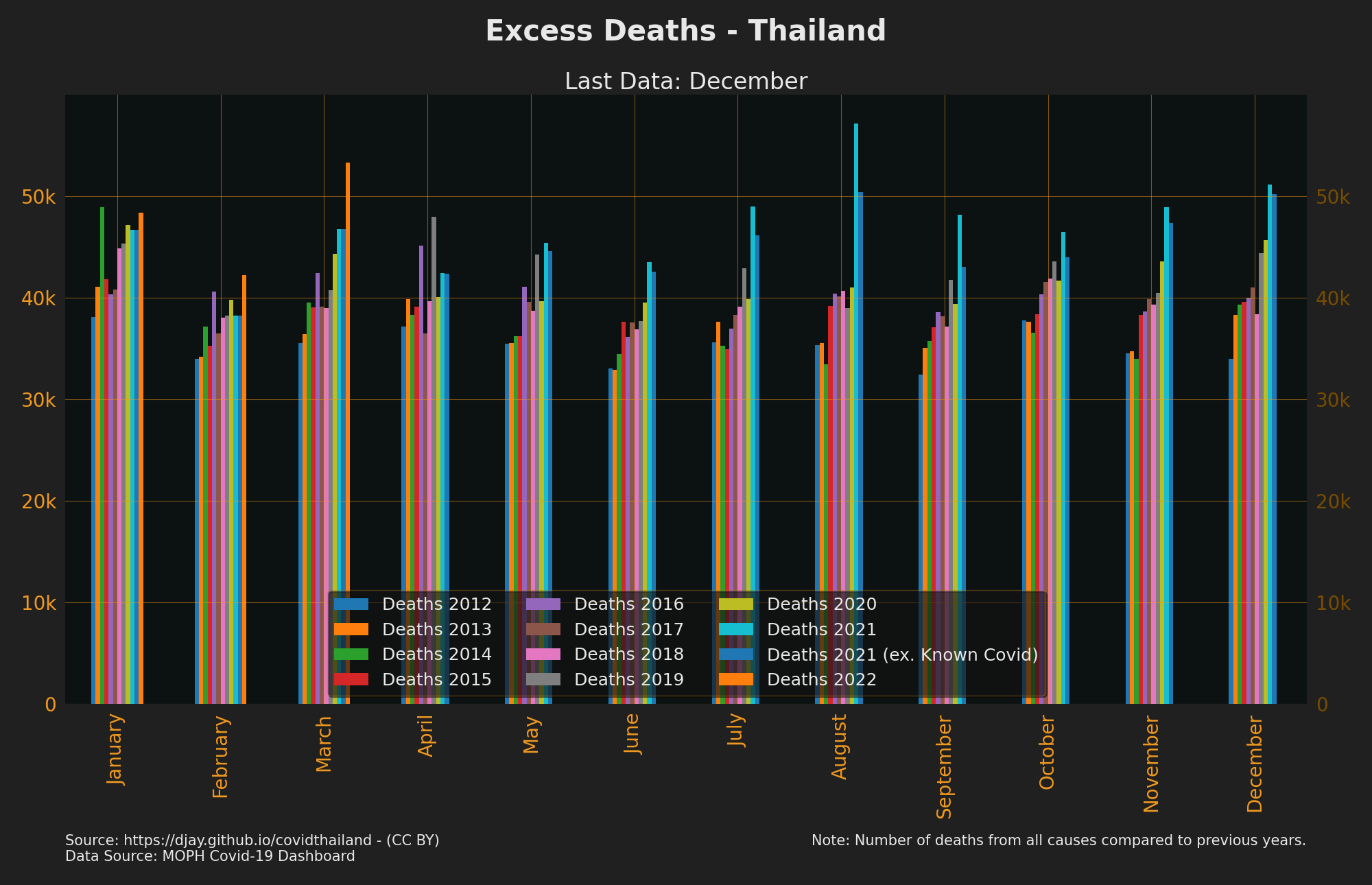
Notes
- 2019 had an unusual increase in deaths compared to the previous 4 years but is unclear yet why. Links excluding 2019 have additionally been included as it’s not yet clear which range of years provides the best baseline to compare against.
- Compare Excess deaths across countries with OWID Excess Deaths or Economist Excess Death Tracker.
- Source Office of Registration Administration, Department of Provincial Administration
How to contribute
- As the different sources of the data has increased so has the code needed fetch, extract and display this data. All the code is fairly simple python however. It is a fun way to learn scraping data and/or pandas and matplotlib.
- Find a github issue and have a go. Many are marked as suitable for beginners
- making new plots
- improve existing plots
- adding tests so it’s faster to make future fixes
- improving scrapers that miss past data, e.g. vaccination reports
- Spotting breaking updates and submitting a pull request to revise the scraper
- If unsure if you are on the right track, submit a draft pull request and request a review
- Spotted a problem or got an idea how to improve? Submit an issue and then have a go making it happen.
- Got Questions? Start a discussion or comment on an issue
Install
-
To install (requires python >=3.9)
python -m venv .venv .venv/bin/pip install -r requirements.txt
Adding tests
-
To run the tests (will only get files needed for tests)
bin/pytest -
To add a test
- Only add test data for dates where the format changed and so the scraper had to get updated. See commit history for dates where this happened or use code coverage.
- Logs from a full scrape can be used to also identify files/dates that are not scraped correctly
- if you are trying to add in past regression tests you can also use
git blame covid_data.pyon the scraping function to see the dates that lines were added or changed. in some cases comments indicated important dates where code had to change.
- if you are trying to add in past regression tests you can also use
- Add empty file in tests/scraper_type/dl_name.json
- for some tests can be use date of file instead or filename.date.json (the date is ignored but helps for readability)
- Run tests. This will download just the document needed for that test, scrape it and compare the results against the json.
- of course this will fail but you can look at the generated data and compare it to the original file or other sources to make sure it looks right
- If the results are correct there is commented out code in the test function to export the data to the test json file.
- if you are using vscode to run pytests you need to refresh the tests list at this point for some reason
- Note that not all scrapers have a test framework setup yet. But follow the existing code to add one or ask for help.
Running just plots (or latest files)
-
To get latest files; change into the root directory of your clone of the repository and then:
wget https://github.com/djay/covidthailand/releases/download/1/inputs.tar.gz && \ tar xzf inputs.tar.gz && \ rm inputs.tar.gz -
To build the CSV files needed for plotting from the inputs downloaded above, from the root directory of the repo, run:
USE_CACHE_DATA=True python covid_data.py -
To do just plots
USE_CACHE_DATA=True MAX_DAYS=0 bin/python covid_plot.py -
When debugging, to scrape just one part first, rearrange the lines in covid_data.py/scrape_and_combine so that the scraping function you want to debug gets called before the others do
Running full code (warning will take a long time)
You can just use the test framework without a full download if you want to work on scraping.
- to download only the files that interest you first, you can comment out or rearrange the lines in covid_data.scrape_and_combine
-
to work on plots you can download the csv files from the website into the api directory and set env MAX_DAYS=0
-
To run the full scrape (warning this will take a long time as it downloads all the documents into a local cache)
bin/python covid_plot.py
Contributors
- Dylan Jay
- Vincent Casagrande
- Peter Scully
- Jonathan Barratt sponsored by Intelligent-Bytes
- join us?
About
Made with python/pandas/matplotlib. Dylan Jay gave a talk on how easy it is to extract data from PDFs and powerpoints and plot data at Bangkok’s Monthly ThaiPy Event Video: “How I scraped Thailand’s covid data” (1h mark)
Why do this? Originally to answer the question “Was Thailand doing enough testing?” for myself and because  .
.
License
!
This work is licensed under a Creative Commons Attribution 4.0 International License.
Other sources of visualisations/Data for Thailand
- Our World in Data: Thailand Profile - the best way to compare against other countries
- Pete Scully: COVID-19 Thailand Public Data for added visualisations and comparisons
- The Researcher Covid Tracker
- Stefano Starita - more excellent analysis and visualisations
- Richard Barrow - maybe the fastest way to get COVID-19 updates in English
- Thai Gov news feeds
- Thai Gov Covid Information: FB - has daily briefing infographics and broadcast (eng and thai) updated quickly
- Thai Gov Spokesman: FB,
- Thai Government PR: FB,
- Ministry of Health: Twitter,
- DMSC PR: FB
- MOPH ArcGIS - PUI + worldwide covid stats
- MOPH OPS Dashboard: ArcGIS - current usage of hospital resource but seems no longer updated (since mid last year?)
Change log
- 2021-08-16 - Move ATK to tests plot and remove from types plot
- 2021-08-16 - Plots of more age ranges for deaths, excess deaths and cases
- 2021-08-15 - Dashboard parsing for provinces and ages with downloads
- 2021-08-02 - Add ATK cases parsing from dashboard and put in case_types plot
- 2021-07-30 - Add plots for excess deaths
- 2021-07-18 - Add data on vaccines by manufacturer from vaccine slides
- 2021-07-17 - Add estimate of death ages
- 2021-07-13 - Remove import vaccines due to coldchain data being restricted
- 2021-07-10 - Switch province plots to per 100,000
- 2021-07-10 - Put actuals on main case plots
- 2021-06-29 - Use coldchain data to plot deliveries and province vac data
- 2021-06-22 - Add trending provinces for contact cases
- 2021-06-12 - Add vaccination daily and improve cumulative vaccinations
- 2021-06-05 - update vaccination reports to parse summary timeline data only (missing source)
- 2021-06-30 - death reasons and hospitalisation critical plots
- 2021-05-21 - Estimate of infections from deaths
- 2021-05-18 - Include prisons as separate province/health district (because briefings do)
- 2021-05-15 - improve highest positive rate plot to show top 5 only
- 2021-05-10 - parse unofficial RB tweet to get cases and deaths earlier
- 2021-05-07 - add trending up and down provinces for cases
- 2021-05-06 - add top 5 fully vaccinated provinces
- 2021-05-05 - added recovered to active cases
- 2021-05-04 - plots of deaths and vaccinations
- 2021-04-28 - rolling averages on area graphs to make them easier to read
- 2021-04-25 - Add graph of cases by risk and active cases (inc severe)
- 2021-04-25 - Scrape hospitalisation stats from briefing reports
- 2021-04-23 - Fixed mistake in testing data where private tests was added again
- 2021-04-22 - data for sym/asymptomatic and pui private vs pui public
- 2021-04-20 - Added case age plot
- 2021-04-18 - Added clearer positive rate by district plot and made overall positive rate clearer
- 2021-04-15 - Quicker province case type breakdowns from daily briefing reports
- 2021-04-13 - get quicker PUI count from https://ddc.moph.go.th/viralpneumonia/index.php
- 2021-04-12 - Put in “unknown area” for tests and cases by district so totals are correct
- 2021-04-05 - add tweets with province/type break down to get more up to date stats